- Home
- Our vision
- Our values
- Members
- Access
- Blog
- Contact
- Language

When I was a student, we had to find a good book first before starting study. But it took a long time before I came across a good book. Now we can find a good book as soon as you search, and you can read good information on the web without purchasing a book (thanks google). Many MOOC lectures at the university level are free, so people with motivation can learn as much as you like. Recently, I am concentrating on learning artificial intelligence related technology, but I feel that I could learn efficiently at very low cost by using the net. I would like to thank the net related technology.
Since I am a patent attorney, I am interested in patent rights of inventions, but I always think that we need to understand technology deeply first before thinking strategy of the rights. Therefore, I believe that deep understanding of technology is extremely important to me even for artificial intelligence related technology. For deep understanding, I thought that development was the best and tried to simulate the development of technology to achieve a specific purpose. Through simulated experiences of development, I aim to study the patenting strategy of artificial intelligence related technology. I got some results, so I will record the result of learning.
The outline of development is as follows.
· Target: Development of artificial intelligence that identifies the author of the patent specification from the features of the patent specification.
· Usage technology: Neural network.
The neural network adopted is as shown in Figure 1 below.
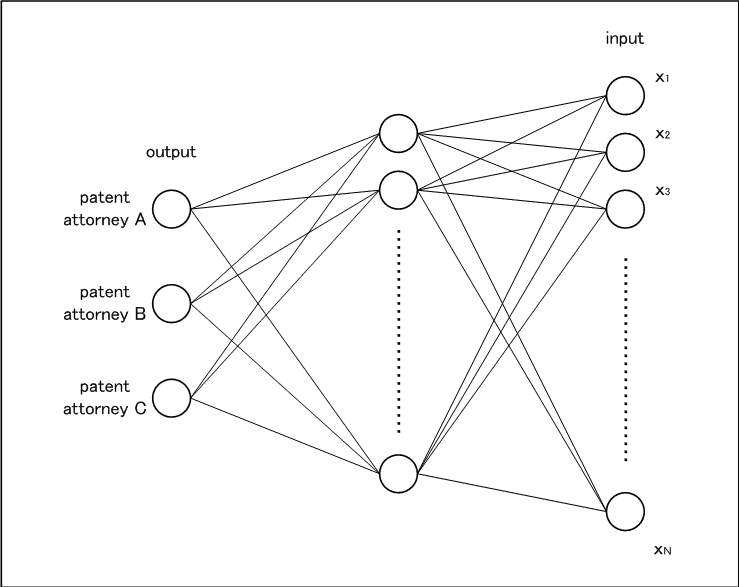
Fig. 1
There are three patent attorneys in our office. Comparing the publications of the specifications written by each patent attorney, it seems that each specification has its own style. Therefore, if the analysis result of each patent attorney’s specification is used as input data and three nodes corresponding to patent attorneys’ A to C are used as output data, I thought that we could develop a neural network which inputs features of the specification and outputs the author. The output node is made to correspond to each patent attorney (the maximum value of the output of the node is the estimation result of the author). And it seems that we can develop a neural network which can obtain meaningful output by determining input data, and by choosing an appropriate neural network. First of all, we need to determine input data. In the meantime, the neural network is configured to have one hidden layer as shown in Fig. 1, and a number of nodes of the hidden layer are constructed by a middle number between the number of input nodes and the number of output nodes. I thought of 3 patterns of input data. 1. Habit of document expression. 2. Habit of flow of logic. 3. Both habit of document expression and habit of flow of logic. Since both features do not depend heavily on the technical field and appear more or less in all the specifications, if we can quantify these features, we will able to estimate the input data corresponding to the author can be created.
Once we have decided on such a development policy, the next is practice. We prepared 130 patent specifications written by each patent attorney. We convert these into text data, statistically process text data from multiple points of view, and use the multiple values obtained as input data. Through such preprocessing, we prepared 390 teacher data (pairs of input data of multiple nodes correspond to one of patent attorneys A to C).
This time we have 300 of training data and 90 of test data. From the training data, 50,000 iterations were performed using data representing habit of document expression, the accuracy of training data was 96% (train.acc), and the accuracy of test data was 88% (test.acc).
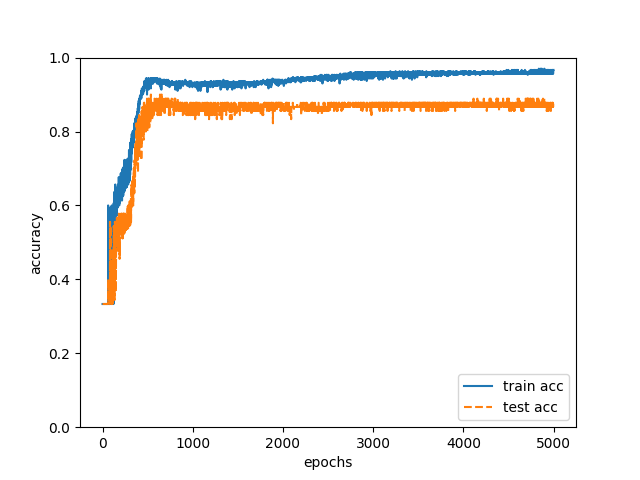
Fig. 2
88%! I am surprised. It is too much success, isn’t it? There is still much room for improvement, such as obvious over learning.
Normally when I read the specifications written by each patent attorney, I can presume that “this specification is likely written by patent attorney A” and so on. But it is surprising that a neural network can presume the author of specification with probability of about 90%. Surprisingly the habit of the author appears quite obviously in the specification. It is impossible for humans to estimate authors with this accuracy, right? I realized the potential of the neural network.
Well, as this entry becomes long, I will describe the concrete analysis next time.
The second entry is here.
The third entry is here.
The fourth entry is here.
· References.;
“Making Deep Learning from scratch” O’Reilly Japan. Yasuhiro Saito. The explanation was very easy to understand. Without this book I think that I could not get the result of this.
“Introductory programming for language research” Kaitaku-sha Yoshihiko Asao, Lee Je Ho.
“Deep.Learning”, https://www.udacity.com/course/deep-learning-ud 730. It is a lecture that gave me a chance to learn Deep Learning by myself.
![]()