- Home
- Our vision
- Our values
- Members
- Access
- Blog
- Contact
- Language
Logo of TensorFlow (eg this link) always reminds me of the role of a patent attorney. This logo looks T in one direction and F in another direction. I always think that as a patent attorney I should face a meeting with such a stance. The invention will be totally different when you change your perspective.
TensorFlow. If you are interested in artificial intelligence, I think you have heard it before. There may be many who have actually tried it out. It seems that it has been a while since open source conversion. Not limited to TensorFlow, various libraries for artificial intelligence development are released free of charge. I did not know that such a library was released for free until I heard the news on public release of TensorFlow, so I was a little shocked when I heard the news.
With TensorFlow, it will be possible for amateurs (eg myself) to develop technology to solve familiar problems with just ideas and a little programming knowledge. Until a while ago, I think that technology development was like a kind of privilege, which is realized by human resources who acquired expertise belonging to the development department with well-developed environment. However, if anyone can use the library for free, there is no barrier to at least part of artificial intelligence development, and it seems that anyone can become a developer. If you collect source data on the net and do machine learning using TensorFlow, I think that you can do quite a lot. Actually, a lot of articles are posted on the net such as “I tried ○○ with TensorFlow”. The world where development barriers fell. It seems like a very good world as an ordinary person. Because there is a possibility to create meaningful things from a little idea.
On the other hand, if you look at the world as an applicant who invests development, I think that it is quite a difficult situation. Compared to other technologies, artificial intelligence related technology seems to raise very rapidly the level of technology considered to have inventive step. While developers with specialized knowledge advance development using their own facilities, even those who do not have expert knowledge can try out their own ideas. And, if some achievement is obtained, there are many people who publish it on the net. These acts increase the prior arts that are the basis of the inventive step judgment at an extremely fast rate. At least it seems that the level of inventive step will rise much easier compared to general fields such as automobile engine development where special environments are essential. I think that it has become a serious era. Companies that intend to develop artificial intelligence related technology and intend to get a patent seem to need to file at a tremendous speed. Few days ago, I have seen the news that artificial intelligence related applications by Japanese companies delay much compared to foreign companies (especially US companies, Chinese companies). I hope that artificial intelligence development in Japanese companies will become active more.
![]()

The first entry is here.
The second entry is here.
The third entry is here.
In the development related to the neural network, it is likely to have many inventions at two stages below.
1. Selection of input data and output data.
2. Structure determination of neural network.
As for 1. mentioned above the decision of input (or output) to achieve the purpose, is an important invention itself. In this development, we confirmed that authors can be estimated with high accuracy using “habit of document expression” and “habit of flow of logic “. And we can say that this way of thinking is the invention. When we use a deep neural network, useful results can be obtained by inputting a large number of data and advancing learning by the deep neural network without considering what input data is important for achieving the purpose. But even so, I think that it is important to identify which of the input data among many input data contributes greatly to the achievement of the purpose. Because the claim should write essential elements only.
Various strategies are conceivable as a patenting strategy when the essential input data A can be identified. I would like to pick up some of them here and write.
First of all, I would like to mention some of the strategies for expressing devices that estimate with learned data as the following claims.
“An apparatus C comprising:
an acquiring unit for acquiring input data A,
a converting unit for converting the input data A into output data B based on machine-learned information, and
an estimating unit for estimating “something” based on output data B.”
· Input data A (possibly also output data B) is a feature of the invention, and the process of machine learning is not characterized. As experienced in the 1st to 3rd entries, determining the input data is an invention and it can be said to be an important factor to achieve the objective.
· In addition, it is considered that there are many cases that a neural network can advance machine learning with well-known technologies (examples shown by the 1st to 3rd entries seem to correspond to this case). For devices that do not learn after learning with learned data, it is important to make a claim that does not include a learning unit that performs machine learning as an element. If the learning unit is included in the element of claims, injunction by direct infringement against an apparatus that is learned before shipment and not learned after shipment will be impossible.
· However, it will be necessary to take countermeasures in the claims or specifications so that they are not obscured by the phrase “based on machine learned information”. In the case where the technique for advancing machine learning is generic, we should explain the technique is generic and we should give some examples. And if it is not the feature of the invention, its reason should be described in the specification and satisfy the enabling requirement.
· Since parameters after machine learning, such as weighting factors, bias, etc., are created by machine learning, we think that it is preferable to write a specification so that it meets the criteria for product by process examination.
· Since the feature of the invention lies in the input data A, we think that it is preferable to develop the features of input data from a superordinate concept to a subordinate concept. In the case of the 1st to 3rd entries, there are many perspectives such as statistics of punctuation marks, statistics of conjunctions, statistics of end-of-sentence expression.
Next, I would like to mention some strategies when we make following claims of an apparatus that can learn.
“An apparatus D comprising:
a learning unit for learning a parameter for converting the sample input data a into the correct data b based on a set of the sample input data a and the correct data b,
an acquiring unit for acquiring the input data A, and
a conversion unit for converting input data A to output data B.”
· This claim will be effective if products that users can conduct learning and conversion (conversion of input data A to output data B) are sold.
· It is worth considering to make a claim that a learning apparatus comprising a learning unit (a device not equipped with acquiring unit and conversion unit).
· Only essential pairs of sample input data a and correct answer data b should be written in independent claims, and other pairs examined in the development process (for example, groups that contributed to improve the accuracy rate but are not the most important) should be written in the dependent claims.
· If the user lets the device learn, the method claim is effective.
Finally, as for the structure of the neural network, I think that the structure of the neural network is patentable if the structure of the neural network has novelty and has the inventive step. However, in this case it is thought that it is necessary to carefully prepare claims. Even the claims featured by the structure of the neural network are patented, it is often difficult to prove that the suspected product of a third party is using the claims. Since it is expected that the structure of the neural network is often a black box when viewed from the outside, there are many cases where it is not effective even if the structure of the neural network itself is patented. If it is virtually impossible to prove that a suspected product of a third party is using that claim, it is meaningless to file for infringing goods countermeasures. If there is no other circumstance (for example, sooner or later it will be announced at the academic conference), I think that we should think carefully whether we should apply for the application or not.
· If it is necessary to patent the structure of the neural network, we think that it is necessary to find features that can be observed when analyzing a device that uses the structure of the neural network. In the meeting before the patent application, it is necessary to find the observable features. If we cannot find the observable features, I think we have to ask the inventors to analyze for finding features.
Although it is not a structure of a neural network, it is considered effective to apply parameters optimized by machine learning. For example, it is conceivable to specify the optimal numerical ranges such as the composition of the functional material and the temperature, pressure, etc. when preparing the material by machine learning, and the numerical range of that is claimed. It is normal practice to describe actual measurement results within the numerical range and actual measurement results at the boundary of the numerical ranges in the specification. But by describing the process of deriving the numerical range by machine learning in the specification, is it possible to satisfy the description requirements (enforceability requirement etc.) of the specification? If the numerical range is obtained by machine learning and the effect in that range is logical, the specification is described so that the invention in a specific numerical range can be implemented by showing the process of machine learning, I feel that the cases where the description requirements are satisfied may come out. It is unknown at this moment how examiners and judges think, but it seems like an interesting topic.
![]()
The first entry is here.
The second entry is here.
In the 1st and 2nd entries, we showed that the authors of the specification could be estimated with high precision in the neural network. However, in the 1st and 2nd we only changed the input data. In the development of the neural network, the structure of the neural network is considered to be a big theme. When we develop the neural network, the structure of the neural network such as the number of layers and the number of nodes will be the subject of consideration first. But as is well known, it is important to change the initial value and use various optimization methods (The first and the second were all SGD). Various methods are conceivable, but first of all it is possible to make the layer deep. Since there are only 18 items (the number of input nodes) in this development, it can be anticipated that a large number of layers will not be required.
For the time being, we learned the hidden layer as two layers (13 nodes, 8 nodes) by using training data and test data of “Both habit of document expression and Habit of flow of logic”. The result is 98% correct answer rate. About 90 cases of test data it means 2 incorrect answers. It is a very high accuracy rate. For this matter, we can say that a deep neural network is not necessary. It is understandable. We have too few input nodes. The sample was inappropriate to simulate the development of the deep neural network. Well, even though the sample was inappropriate, I think that the high accuracy rate is accomplished because the input data was suitable for estimation of the author.
Initially, I wanted to improve the rate of correct answers gradually while using modern technic like a self-encoder (ten years have passed since self-encoder became a topic). In addition, not only simple neural networks, but also the complicated structure of the network, such as inputting the output of one node to the other node in the same layer, there are various ingenuity in the structure of the network. However, judging from the results so far, it seems that there is not enough sample to be able to judge the structure of the neural network and the usefulness of various techniques in the current sample. Although there may be room for further improvement, even if the correct answer rate becomes 100%, I cannot conclude the reason of high accuracy rate is achieved by the structure change of the neural network. It can be just a coincidence. Therefore, I would like to try development with a self-encoder etc. in another project in the future (I think that it is good to experience the development with word 2vec and Q learning at present).
Now, since I first experienced the development process related to the neural network in the 1st to 3rd entries, I would like to think about the patenting of the invention which can occur in the development process next time.
The fourth entry is here.
![]()
The first entry is here.
In the first entry, we showed that we could estimate the specification authors with high precision in a simulated developed neural network. In the development process, the neural network learned based on the following three patterns of input data.
1. Habit of document expression.
2. Habit of flow of logic.
3. Both habit of document expression and Habit of flow of logic.
Below, I will concretely describe each pattern.
1. Habit of document expression.
This is the plan mentioned in the 1st entry. In this plan, the following 11 items were digitized for each specification before learning. Number of lines of main claim, number of characters of main claim, average number of lines of subclaims, average number of characters of subclaims, number of commas per line of claims, number of characters per line of claims, average number of commas per paragraph of the specification, average number of characters per paragraph of the specification, number of commas per specification, number of characters per specification, the number of characters of the specification.
Details of learning are as follows.
· Training data: 300 data correlating the numerical values of 11 items with the author.
· Test data: 90 data correlating the numerical values of 11 items and the author.
· Hidden layer: One layer with 7 nodes.
· Mini batch: about 10 to 50.
· Optimization method: stochastic gradient descent.
· Iteration: 50000 times. By doing the above learning with training data and estimating 90 authors of test data in the neural network after learning, the correct answer rate was 88% (Fig. 1).
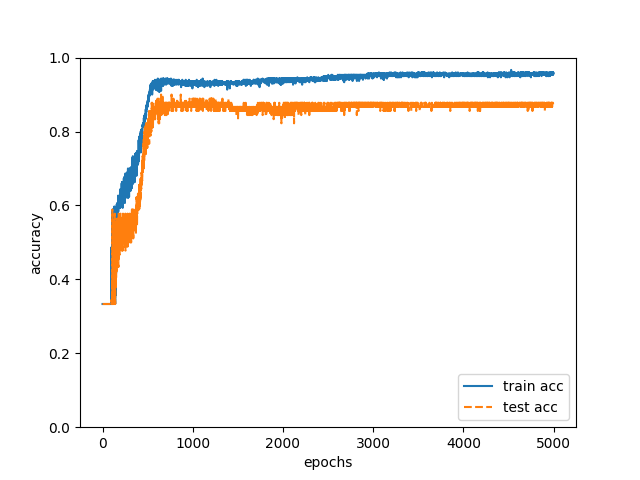
Fig. 1
2. Habit of flow of logic.
In this plan, we measured the number of seven words below for each specification before learning.
“However”, “still”, “namely”, “also”, “further”, “could be “, “and”.
I often write sentences in the description in the order of “assertions, commentaries, arguments, and exemplification” in order to explain logically. When writing sentences in this order, “namely” appears before “commentary”. Since the habit of logical explanation differs for each author, I thought that the authors can be identified by statistically processing the words in the first part and the last part of the paragraph. The details of learning are the same as “1. Habit of document expression” (however, the number of nodes in the hidden layer is five). By doing the above learning with training data and estimating 90 authors of test data, the correct answer rate was 79% (Fig. 2).
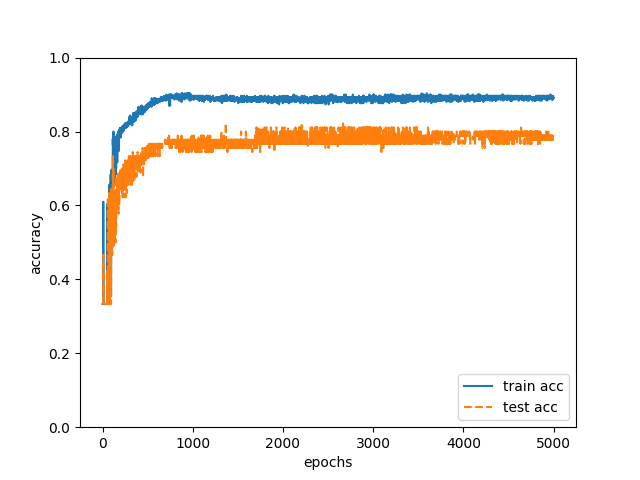
Fig. 2
As described above, the correct answer rate of 79% was obtained when “1. Habit of document expression ” was used as input data, and the correct answer rate of 88% was obtained when “2. Habit of flow of logic” was used as input data. This result was different from my intuition, so I was a little puzzled. If I estimate authors by myself, I pay attention to logic flow more than the number of punctuation marks.
Although “2. Habit of flow of logic” may have disadvantage because the number of items is small, I can say that “1. Habit of document expression ” is effective to estimate the authors. Based on this result it is impossible to exclude the idea that “1. Habit of document expression” can be used as input data if seriously applying for a patent.
Furthermore, although the percentage of correct answers is somewhat reduced, the correct answer rate of 79% can be obtained even in “2. Habit on flow of logic “, so if you apply for a patent, applicant should not omit “2. Habit of flow of logic ” from claims.
A significant correct answer rate was obtained when one of “1. Habit of document expression” and “2. Habit of flow of logic” was used as input data, so it will be possible to estimate more accurately if both are set as input data.
Therefore, I let the neural network learn based on “3. Both habit of document expression and habit of flow of logic”. We created training data and test data by combining the input data used in “1. Habit of document expression” and “2. Habit of flow of logic”. The detail of learning is the same as “1. Habit of document expression” (nodes of the hidden layer are 11). We conducted the above training with training data and estimated the authors of 90 test data in the neural network after learning, the correct answer rate was 93% (Fig. 3). 84 of the 90 test data have been able to accurately estimate the author.
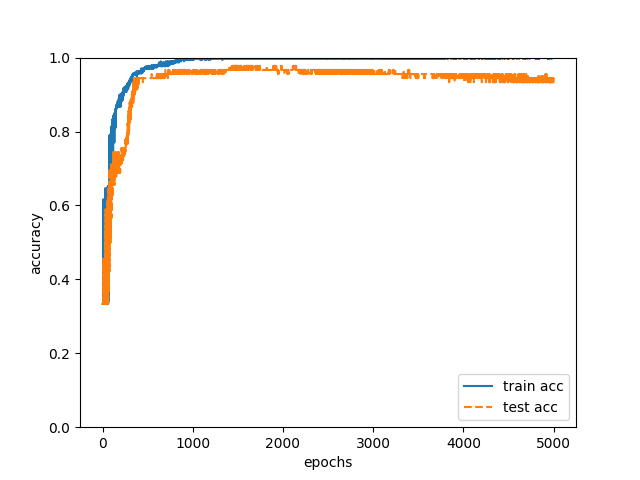
Fig. 3
It was proved to be effective that “1. Habit of document expression” “2. Habit of flow of logic” “3. Both habit of document expression and habit of flow of logic ” are very useful as input data for estimating the author of the specification. On the other hand, in developing neural networks, it is necessary to optimize the structure of the network. Next time we will report the result of changing the structure of the network.
The third entry is here.
The fourth entfy is here.
![]()
When I was a student, we had to find a good book first before starting study. But it took a long time before I came across a good book. Now we can find a good book as soon as you search, and you can read good information on the web without purchasing a book (thanks google). Many MOOC lectures at the university level are free, so people with motivation can learn as much as you like. Recently, I am concentrating on learning artificial intelligence related technology, but I feel that I could learn efficiently at very low cost by using the net. I would like to thank the net related technology.
Since I am a patent attorney, I am interested in patent rights of inventions, but I always think that we need to understand technology deeply first before thinking strategy of the rights. Therefore, I believe that deep understanding of technology is extremely important to me even for artificial intelligence related technology. For deep understanding, I thought that development was the best and tried to simulate the development of technology to achieve a specific purpose. Through simulated experiences of development, I aim to study the patenting strategy of artificial intelligence related technology. I got some results, so I will record the result of learning.
The outline of development is as follows.
· Target: Development of artificial intelligence that identifies the author of the patent specification from the features of the patent specification.
· Usage technology: Neural network.
The neural network adopted is as shown in Figure 1 below.
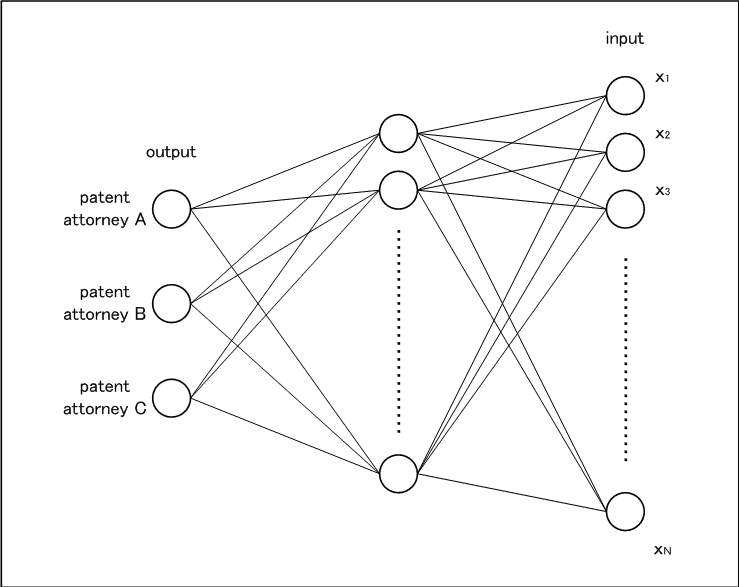
Fig. 1
There are three patent attorneys in our office. Comparing the publications of the specifications written by each patent attorney, it seems that each specification has its own style. Therefore, if the analysis result of each patent attorney’s specification is used as input data and three nodes corresponding to patent attorneys’ A to C are used as output data, I thought that we could develop a neural network which inputs features of the specification and outputs the author. The output node is made to correspond to each patent attorney (the maximum value of the output of the node is the estimation result of the author). And it seems that we can develop a neural network which can obtain meaningful output by determining input data, and by choosing an appropriate neural network. First of all, we need to determine input data. In the meantime, the neural network is configured to have one hidden layer as shown in Fig. 1, and a number of nodes of the hidden layer are constructed by a middle number between the number of input nodes and the number of output nodes. I thought of 3 patterns of input data. 1. Habit of document expression. 2. Habit of flow of logic. 3. Both habit of document expression and habit of flow of logic. Since both features do not depend heavily on the technical field and appear more or less in all the specifications, if we can quantify these features, we will able to estimate the input data corresponding to the author can be created.
Once we have decided on such a development policy, the next is practice. We prepared 130 patent specifications written by each patent attorney. We convert these into text data, statistically process text data from multiple points of view, and use the multiple values obtained as input data. Through such preprocessing, we prepared 390 teacher data (pairs of input data of multiple nodes correspond to one of patent attorneys A to C).
This time we have 300 of training data and 90 of test data. From the training data, 50,000 iterations were performed using data representing habit of document expression, the accuracy of training data was 96% (train.acc), and the accuracy of test data was 88% (test.acc).
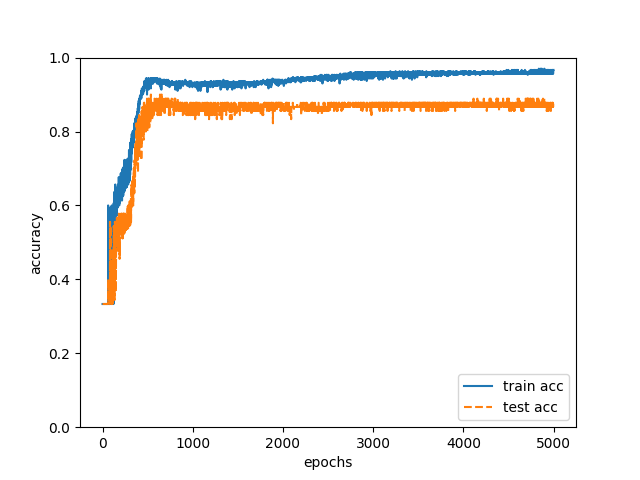
Fig. 2
88%! I am surprised. It is too much success, isn’t it? There is still much room for improvement, such as obvious over learning.
Normally when I read the specifications written by each patent attorney, I can presume that “this specification is likely written by patent attorney A” and so on. But it is surprising that a neural network can presume the author of specification with probability of about 90%. Surprisingly the habit of the author appears quite obviously in the specification. It is impossible for humans to estimate authors with this accuracy, right? I realized the potential of the neural network.
Well, as this entry becomes long, I will describe the concrete analysis next time.
The second entry is here.
The third entry is here.
The fourth entry is here.
· References.;
“Making Deep Learning from scratch” O’Reilly Japan. Yasuhiro Saito. The explanation was very easy to understand. Without this book I think that I could not get the result of this.
“Introductory programming for language research” Kaitaku-sha Yoshihiko Asao, Lee Je Ho.
“Deep.Learning”, https://www.udacity.com/course/deep-learning-ud 730. It is a lecture that gave me a chance to learn Deep Learning by myself.
![]()