- Home
- Our vision
- Our values
- Members
- Access
- Blog
- Join us
- Contact
- Language
モノ、コトのコストがものすごい速さで低下しているように感じます。私が学生の頃は、学習のためにまず良い本を探すところから始めましたが、良い本に巡り会うまでにやたらと時間コストがかかりました。今では検索すればすぐに良い本を見つけられますし、本を購入しなくてもweb上で良い情報を読むことが可能ですね(google先生ありがとう)。大学レベルの講義も多くのMOOCで無料ですので意欲のある人はいくらでも学習できますね。最近、私は人工知能関連技術の学習に注力していますが、ネットを利用することで極めて低コストで効率的に学習できたように感じます。ネット関連技術に感謝したい。
私は弁理士ですので発明の権利化に興味がありますが、私自身は、一貫して技術を深く理解した後に権利化の戦略を考えるという立場で仕事をしています。そこで、人工知能関連の技術においてもまず技術を深く理解することが自分にとって極めて重要と考えています。深い理解のためには自ら開発するのが一番と考え、特定の目的を達成する技術の開発を疑似体験してみました。開発の疑似体験を通じて、人工知能関連技術の特許化戦略を検討することを目標にしています。まだまだ学習は継続しますが、とりあえず一区切りしましたので、何回かに分けて学習成果を記録しておこうと思います。
開発の概要は以下の通りです。
・目標:特許明細書の特徴から特許明細書の執筆者を特定する人工知能の開発
・利用技術:ニューラルネットワーク
要するに、ニューラルネットワークについて私が学習するために、身近な特許明細書を題材にしたと言うことです。採用したニューラルネットワークは以下の図1の通りです。
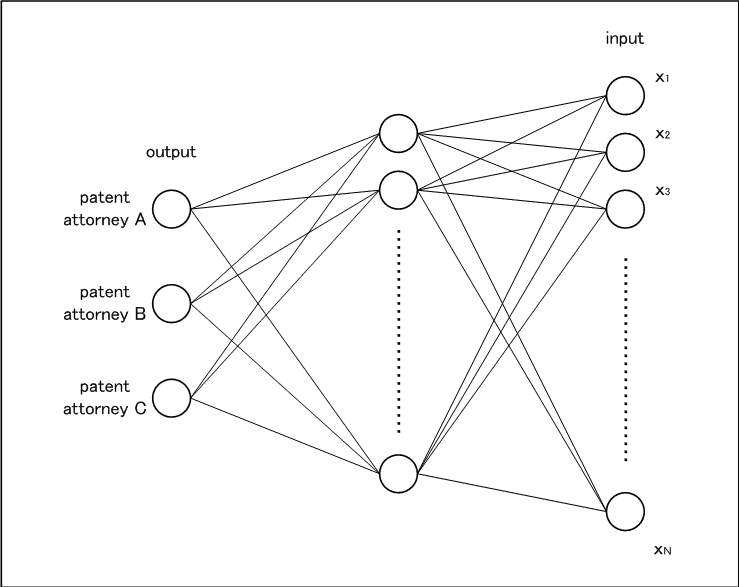
図1
弊所には弁理士が3人おります。各弁理士が執筆した明細書の公開公報を比べると、それぞれの明細書にそれぞれのスタイルがあるように思えます。そこで、各弁理士の明細書の解析結果を入力データとし、弁理士A~Cに対応する3個のノードを出力データとすれば、明細書の特徴を入力し、執筆者を出力するニューラルネットワークを開発できると考えました。
出力ノードは各弁理士に対応させる(ノードの出力の最大値が執筆者の推定結果となる)と決まりました。あとは、1.入力データの決定、2.適切なニューラルネットワークの選定、を行えば、ある程度の出力が得られるニューラルネットワークを開発できそうです。
まずは1.入力データの決定です。とりあえず、ニューラルネットワークは図1に示すように1層の隠れ層を有する構成とし、入力ノードの数と出力ノードの数との中間程度の数で隠れ層のノードを構成しておきます。
さて、入力データは3パターン考えました。
1.文書表現上の癖
2.論理展開上の癖
3.文書表現上の癖と、論理展開上の癖の双方
いずれの特徴も、技術分野に大きく依存せず、全ての明細書に多かれ少なかれ現れるため、これらの特徴を数値化できれば執筆者と1対1に対応する入力データを作成できるのではないかと推定したわけです。
以上のような開発方針が決定したら、次は実践です。
まずは各弁理士の明細書を130件ずつ集めました。これらをテキストデータ化し、テキストデータを複数の観点で統計処理し、得られた複数の値を複数のノードへの入力データとします。このような前処理により、弁理士A~Cのいずれかと複数のノードへの入力データとが対応づけられた教師データを390件生成しました。
今回はこの中の300件をtrainingデータ、90件をtestデータとしました。教師データの中から「1.文書表現上の癖」を表すデータを使って50000回のイタレーションをおこなったところ、以下の図2のようにtrainingデータの正解率(train acc)が96%、testデータの正解率(test acc)が88%になりました。。。。
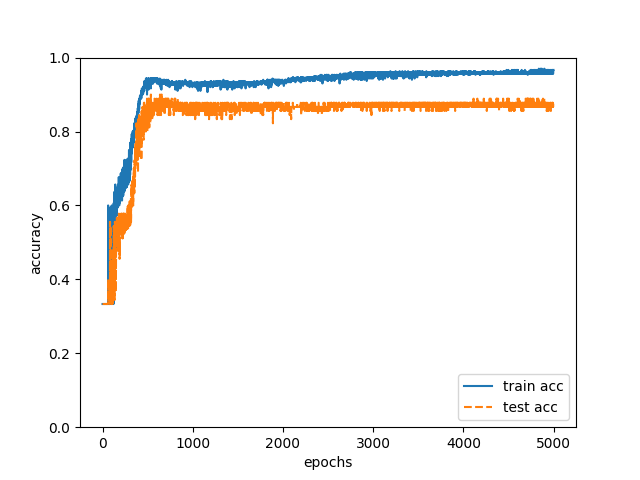
図2
88%。びっくりです。正直うまくいきすぎではないでしょうか。明らかに過学習しているなど、向上の余地はまだまだありますが。普段、各弁理士の執筆原稿を読んでいて、「この明細書は弁理士Aが書いたようだ。」などの推定はできますが、たかが表層的な特徴だけで約90%の確率で執筆者を当てられるなんて。。。意外なことに執筆者の癖は明細書でかなり明らかに現れているのですね。人間にはこの精度で執筆者を推定するなんて到底不可能ですよね。ニューラルネットワークのポテンシャルを実感できました。
さて、長くなってしまいましたので、「1.文書表現上の癖」の具体的な解析、「2.論理展開上の癖」「3.文書表現上の癖と、論理展開上の癖の双方」の具体的な解析については次回に致します。
第2回のエントリはこちら
第3回のエントリはこちら
第4回のエントリはこちら
・参考文献
「ゼロから作るDeepLearning」オライリージャパン 斎藤康毅 著
いくつか読んだ中では解説が大変わかりやすかったです。この本がなければ今回の成果は得られなかったと思います。
「言語研究のためのプログラミング入門」開拓社 淺尾仁彦・李 在鎬 著
明細書のテキストから特徴を抽出するプログラムを作成する際に参考にさせて頂きました。
「Deep Learning」https://www.udacity.com/course/deep-learning–ud730
DeepLearningを自己学習するきっかけを与えてくれた講座です。
