- Home
- Our vision
- Our values
- Members
- Access
- Blog
- Join us
- Contact
- Language
テレビゲーム関連の特許の統計をまとめてみました。
FIをA63F13/00に限定して検索し、出願人毎に年間の件数を集計しました。件数は、公知日が属する年毎にカウントしてあります。A63F13/00は、ソフトウェア寄りの案件の抽出を念頭にしています。ハードウェア用の技術はあまり含まれていません。ハードウェア用の技術を含めると、ソニーさんはとても件数が多くなります。各社さんの業態が違いますので、同じ土俵での比較にはなっていないかもしれませんが、ざっくりと動向を知ることはできるかなと思っています。
図1は集計結果です。企業別に、年間の件数を棒グラフで示しています。積み上げグラフなので棒の全長で10年間の総件数を比較できます。
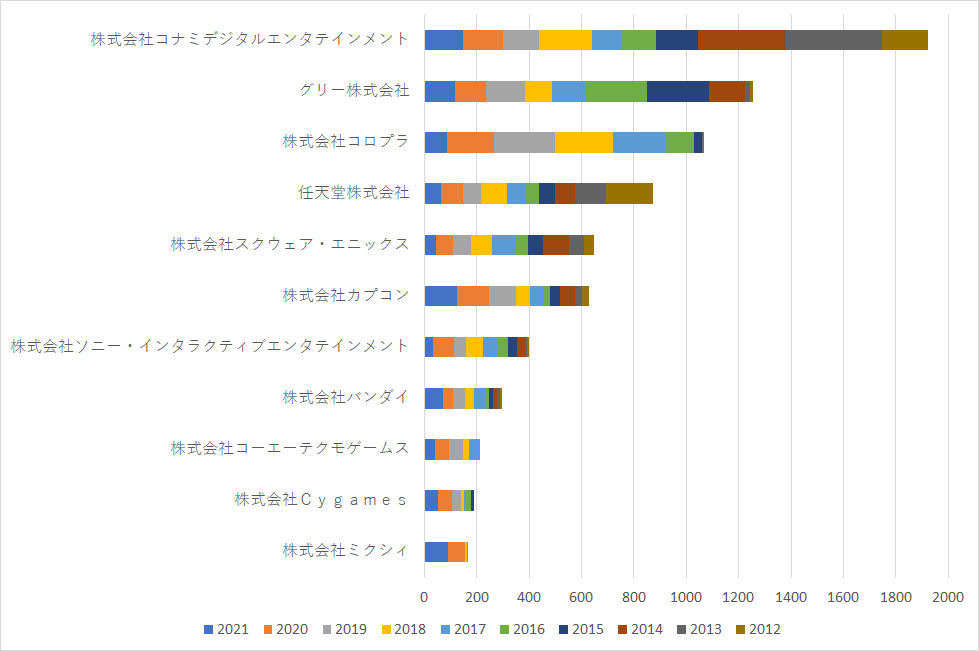
検索し、集計すると、いろいろなことがわかりますね。
まず、コナミさんの存在感。他の企業さんと比較して突出して特許出願の件数が多いのですね。知財を重視されていることがよくわかります。
上位3社は、特定の時期に件数が増加しています。コナミさんは2013,2014年。グリーさんは2014~2016年。コロプラさんは2017~2020年。おそらくは、有名な訴訟の当事者なので、訴訟を受けて出願戦略を立てた結果、攻撃、防御のために選択肢を増やしたと言うことなのでしょうね。カプコンさんが2019年~2021年の出願を多くされているのも同様の理由でしょうか。
多くの企業さんで10年前よりも近年の方が、件数が増加する傾向にあります。近年、ゲーム業界では、大きな特許訴訟が結構な頻度でありますので、各企業さんで対策を打っていると言うことでしょうか。
最強の知財部として名高い任天堂さん。件数は意外と少ない。でも最強と言われている。。。数より質なのでしょうね。
検索条件に登録日ありとすると、登録された案件のみを検出できます。年毎の「登録件数/公知件数」を計算すると、2012以降、大半の企業さんは8割~9割の登録率ですが、5割~6割の登録率の企業さんや、近年、登録率が徐々に低下している企業さんもいらっしゃいます。登録された請求項の質が最も重要なので、登録率の高低が単純に質の高低とはいえませんが、投資を登録に結びつけることを重視するのか、件数を重視するのか、いろいろと企業さんの姿勢が垣間見られます。
最後に、全体を眺めて見ますと、特許出願件数の多寡は、売上の多寡とは必ずしも一致しないことがうかがえます。売上が大きいのはソニーさん、任天堂さん、コナミさん、スクウェア・エニックスさんですが、特許出願件数はコナミさん、グリーさん、コロプラさん、任天堂さんという順位になっています。他社に対向するための特許出願の件数は、自社の売り上げよりも、業界の動向、他社の特許出願件数に依存するでしょうし、訴訟などの個別の事情もあり、相対的に売上が小さい企業さんであっても、他社に対向するために件数を確保しなければなりません。あるいは、相対的に売上が小さい企業さんであっても、特許出願に投資すれば、大手の企業さんに対向できる存在感を持つことができると言えるかもしれません。このような事情はどの業界でも同じと思います。
今後は、有名な特許訴訟や明細書など、個別の事案も研究していこうと思っています。

自転車の技術を少しずつ学習しています。書籍、雑誌も読みますが、やはり私は弁理士ですので、特許公報も読みたくなります。私は、コンポーネントを交換しながら今の自転車に可能な限り長く乗りたいと考えています。交換に際してそれぞれのコンポーネントについて、学習しましたが、コンポーネントの基本は理解しつつあるので、今度は特許公報を見ながら深く学習しようと考えています。まずは、コンポーネントメーカーの出願動向を調べてみました。
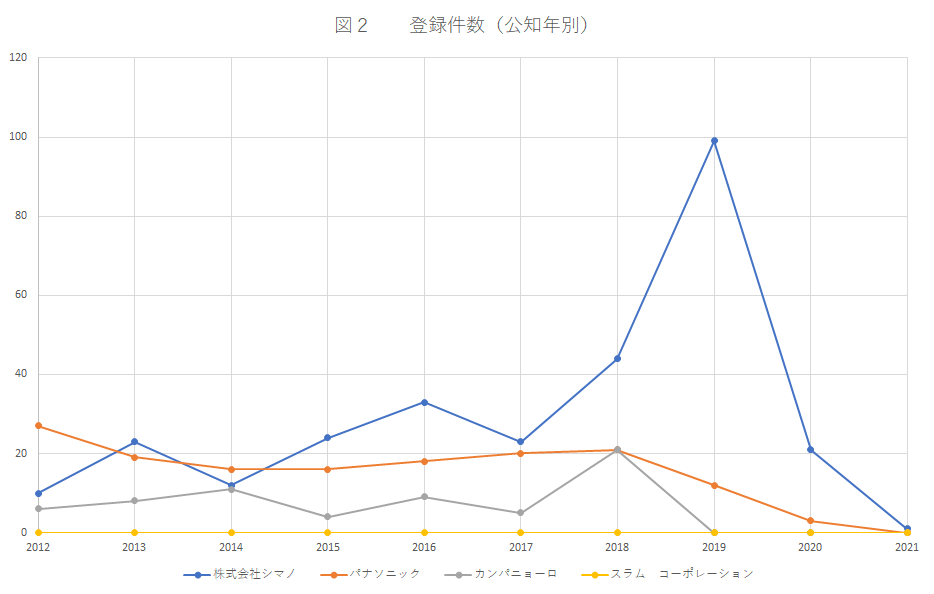
図1は、メジャーなコンポーネントメーカーとパナソニックについて、自転車関係の特許の公開件数を公知年別に集計したものです。出願人&IPC(B62)で検索しました。IPC のB62には自転車以外の車両も含まれますが、検索結果をざっと見たところ自転車関係が大半でした。図2は、図1の結果に登録日ありの条件を追加して集計したものです。
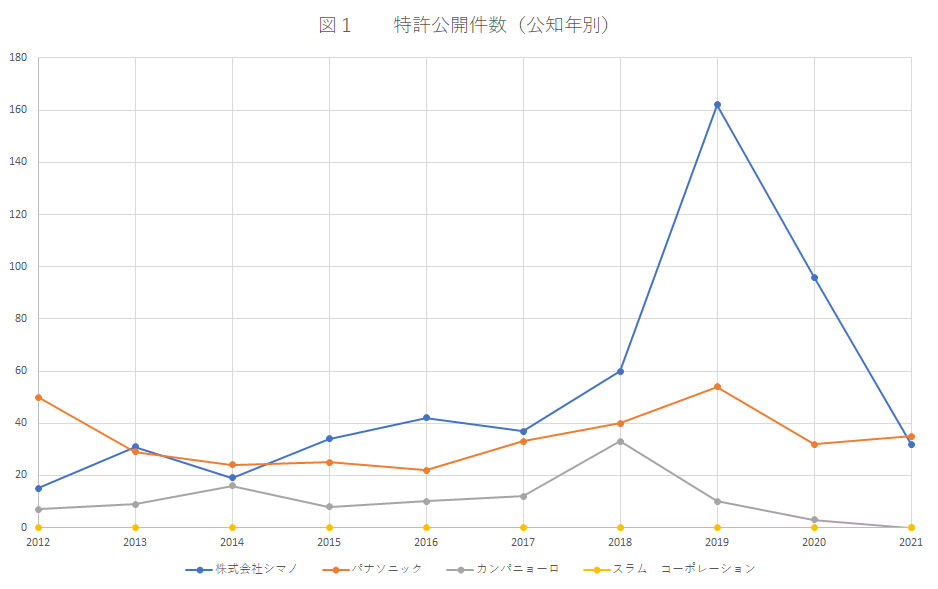
雑誌を読んだり、自転車屋さんで話をしたりしていると、コンポーネントの品質、ブランド力はシマノさん1強という印象がとても強いです。多くの自転車乗りはシマノ製品のファンだと思うのですが、やっぱり私もファンです。自分の自転車のコンポーネントは可能な限りシマノ製品にしています。圧倒的に安心感がありますからね。
シマノさん1強状態は、特許からも裏付けられました。カンパニョーロさんは、外国メーカーとしては日本で結構出願しており、一定の存在感がありますが、シマノさんの件数と比較すると控えめですね。日本の特許に関して、両者は互角ではないようです。
SRAMさんは日本でほとんど出願していないようです。もしかしたら検索方法が悪いかもしれませんが、google patentsでSRAMさんのUS出願を眺めていても、ファミリーに日本が含まれる出願は見当たりません。以上の簡単な検索のみから判断する限り、特許から見てもコンポーネントに関してシマノさんは敵無しのようです。
シマノさんの出願、登録は、2019年に突出して件数が増えています。強い意志が感じられますね。2019年に公知になった公報をいくつか眺めて見ました。どうやら、モータアシストのある自転車、電動コンポーネントや制御系の出願が多いようです。
2019年より少し前に自転車業界で何が起こっていたのか調べていたら、2019年前後の自転車業界の分析をしたこんな記事を見つけました。
激変する自転車部品業界でシマノを襲う二つの波
大変興味深く読ませていただきました。機械式の機構から電動式の機構への移行が進むと、従来と異なる業種と戦っていく必要があるようですね。新興国のメーカーや自動車コンポーネントメーカーとも競合していくかもしれません。上述の検索では、メジャーなコンポーネントメーカーのみについて調べただけなので、機会があれば、メーカーを限定せずに、自転車関連の特許検索をしてみようと思います。
どの業界でも各種の変化に対応していく必要があるのだと思いますが、特許公開件数を眺めていると、シマノさんは、他のメジャーなコンポーネントメーカーよりかなり先行しています。少なくとも特許に関しては日本国内において盤石の地位が維持できるように手を打っているように見えます。日本国内におけるブランド力、特許動向から考えると、当面は盤石、1強状態が続くと予想されますが、はたしてどうなるでしょうか。シマノ製品ファンの私としては、消耗品交換の際にシマノ製品を使いつつ、今後の業界の動向もウォッチしていこうと考えています。
量子コンピュータ関連技術の特許出願について統計をとってみました。
ここ数か月のニュースを見ていますと、人工知能関連のニュースはずいぶん少なくなってきたように思えます。ある開発者さんからは、人工知能で実現できることと実現できないことが少しずつ分かってきたと聞きました。一時期のブームは終了し、より現実的なフェーズに移行したのでしょうか。そういえば、人工知能について流行期が終わり、幻滅期に差し掛かったというニュースもありました。
私は、弁理士という職業柄、最先端のあらゆる技術に興味がありまして、以前から量子コンピュータが気になっていました。
そこで、量子コンピュータ関連の特許出願の動向を調べてみました。統計は、以前人工知能関連技術について実施したものと同様の手法です。(公開年AND量子コンピュータ)で得られた件数を集計しました。検索にはJ-PlatPatとUSPTOのPatent Application Full Text And Image Databaseを使用しました。例えば、米国であれば、公報全文にquantum computerが含まれる2016年公開の出願を、(PD/1/1/2016->12/31/2016 and SPEC/” quantum computer “)というパラメータで検索しました。
このような検索では、一言「量子コンピュータで実現してもよい」と書いた程度の明細書もヒットしますので、検索結果から多くのことを抽出できるとは思いませんが、それでも出願動向はわかるのではないかと考えています。
結果は図1です。棒グラフは量子コンピュータというキーワードを含む出願の公開件数であり、数値は左の縦軸で示されています。折れ線グラフは棒グラフで示された公開件数をその年の全公開件数で除して規格化した値であり、数値は右の縦軸で示されています。
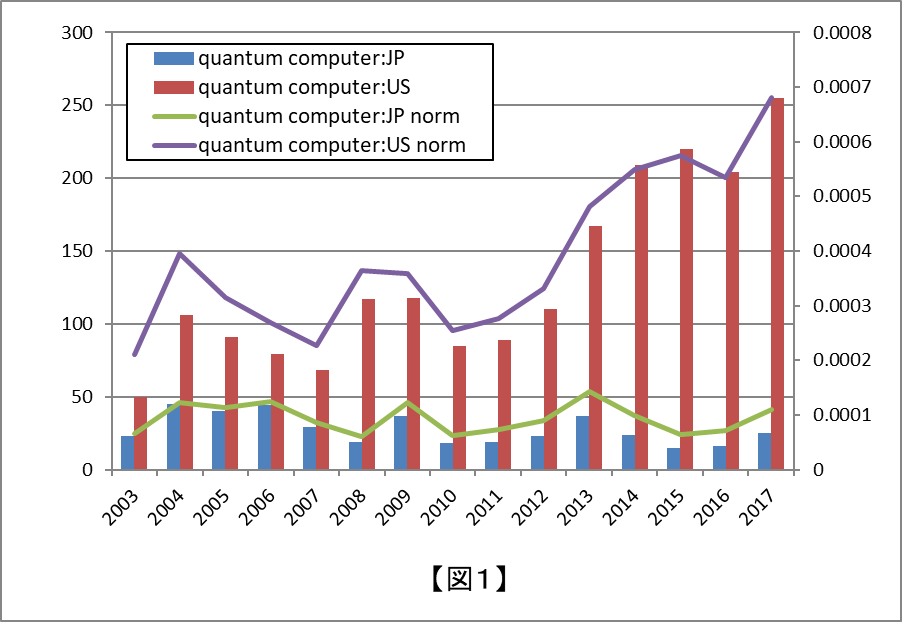
まず、日米双方で出願件数が少ないことに驚きました。最近ですと2020年ごろまでにIBMやGoogleが量子コンピュータのクラウドサービスを始めるというニュースが報じられるなど、新聞等で量子コンピュータのニュースを見ることも増えてきました。そして、それらのニュースは、基礎研究段階を終え、実現が近づいているというニュアンスで報じられることも多いです。
それなのに、日本で50件以下、米国で300件以下の公開数って。。。実際には、まだ技術的なブレイクスルーがなく、実現に必要な要素技術の開発もまだまだ先になるというフェーズなのでしょうか。
日米の差に着目すると、全期間にわたって米国における公開件数が日本における公開件数を圧倒しています。例えば、2016年を見ますと、日米の件数は16件、204件であり、12.75倍もの差があります。この年の米国の公開件数は日本の公開件数の1.68倍でしたので、全産業分野での公開件数の比をはるかに超える差がついてしまっています。ちょっとした衝撃です。今回の検索結果が日米の技術力の差を正確に示していると言う気はありませんが、日米において量子コンピュータの開発成果に埋めようのない差がつくかもしれないという危惧は生じます。
また、2016年の16件という公開件数は、日本国内でほとんど研究成果が出願されていないといえそうな数値です。一昔前までは、量子コンピュータの基礎的な研究において、日本の研究者がある程度の存在感を持っていたと思うのですが、今はどうなってしまったのでしょうか。
特許の統計を集計していると、ほとんどの場合、日本の出願は、2008年頃のリーマンショックの影響で出願数が激減し、その影響が現在でも色濃く残っていることが示唆されます。量子コンピュータの研究や出願もおそらく不況の影響を受けたのだと思いますが、それにしてもこの存在感のなさは衝撃です。まさか、日本での研究成果が日本で出願されず米国のみで出願されているってこともないでしょうし。。。詳細は把握していませんが、量子コンピュータについてもAIと同様に日米で埋めがたい差がついてしまうのではないかと心配になります。私は、理学部の物理学科を卒業し、工学部の応用物理系の大学院を修了しました。その頃、主な科目の中で量子力学が一番楽しかったと記憶しています。いかにも大学で扱う物理のような気がしてまして。弁理士となった後、いつの日か量子コンピュータの出願に携わる日が来ないだろうかと期待していたのですが、上述の検索結果を見ると当面そういう日は来ないように思えますね。。。
先日参加したINTAのミーティングにおいて、私の主な仕事は人に会うことでした。大半は弁理士です。会場で名刺交換をしたり事務所を訪問したり。
そんな中、データサイエンティストの方とお話しさせて頂く機会がありました。この方は、AIの開発に携わっており、データさえあれば何でも学習できるという主旨でお話しをされていました。AIに明細書は書けると思うか?と聞いてみたところ、「データさえあれば」確実にできるということでした。例えば、クレームから明細書を作成するとか、発明提案書から明細書を作成するとか、そういうことが可能であると考えていらっしゃるようです。
また、INTA期間中には夜も人と会う機会がたくさんあり、お酒を飲みながらたくさんの人に会ってきたのですが、その際、明細書の自動作成AIを開発している企業があるという話も聞きました。現在の所、使えるアウトプットが得られるものにはなっていないという話でしたが、世界中で明細書の作成を自動化するための開発を行っていると仰っている方もいました。
私自身は、以前も書きましたように、「データセットを用意することが不可能」であるため、弁理士の仕事を代替可能なAIを近い将来に開発するのは不可能と考えているのですが、明細書の作成を支援するAIなら開発できるかもしれないとも考えています。例えば、特定のクライアント様の明細書を書く際に、装置の基本構成などを既存の明細書から流用し、適切な表現となるように修正する「作業」を行うことがありますが、このような「作業」であれば「正解」と見なして良い文書が存在し得るため、データセットを用意することも不可能ではないように思えます。従って、このような「作業」を行うAIであれば機械学習によって開発できるように思えます。もちろん、AIのアウトプットを適宜修正するのは必須になると思いますが、むしろ、「作業」を弁理士の代わりに実施してくれるAIがあるなら是非使いたいです。作業的な部分はAIに任せておき、クライアント様の個別の事情に合わせるべきクレームやクレームのサポート部分に注力できるようになれば、限られた時間で作成できるクレームや明細書の品質を高められるように思えます。10年後には我々の業界も今とは仕事の内容が大きく変わっているかもしれませんね。
弁理士業界は年度末に繁忙期がありますが、年度開始当初は比較的時間があります。多くの弁理士は春に自己研鑽されているのではないでしょうか。
今年はアメリカ、シアトルで開催されるINTAのミーティングに参加しますので、この機会に米国特許法の知識をリフレッシュ中です。
また、ここのところ私は人工知能の関連技術に非常に強く惹かれていまして、時間のあるときにより多くの知識を吸収しようと思っています。
近年、MOOCをはじめとする学習環境がとても充実していますので、学生でなくても容易にハイレベルな教育を受けることが可能ですね。もちろん、書籍を利用して学習することも可能ですが、実際にコーディングしながら学習を進めるためにMOOCの講座を利用することにしました。
ざっと調べただけでも人工知能に関する学習が可能なオンラインコースは非常にたくさんあります。今回、以下を検討しました。
・COURSERA: Deep Learning Specialization
・UDACITY: Artificial Intelligence
・Machine Learning Crash Course
・GCIデータサイエンティスト育成講座
最初の2講座は有料です。無料体験などを使いながらそれぞれを試してみた結果、COURSERAの講座を受講することに決めました。同じ講座を受講中の方がいらっしゃいましたら是非一緒に勉強しませんか。一人より、多人数で勉強した方が理解も深まりますので。
UDACITYは最後まで迷いました。他の講座にはない非常に興味深い課題ばかりだったからです。数独を解くコードやゲームを自律的にプレイするエージェントの作成が課題になっています。COURSERAの講座と比べると要求されるバックグラウンドが高いこともあり、UDACITYの方がまともにコーディングする量が多かったです。これが非常に楽しかったのですが、期限がタイトで、課題の提出が最終期限に間に合わなかった場合には修了できなくなってしまいます。職業プログラマーではない私のような者は、pythonの文法を調べた上でコードを書く必要があるため、デバッグの際にロジックが良くないのか文法が良くないのか判断できず、デバッグに非常に時間がかかります。通常業務終了後の空き時間で課題をこなすためにはここがネックになりまして、受講を断念しました。
COURSERAの講座は人工知能に関する基礎的なトピックを説明し、コーディングによって体験することで理解を深める体裁になっています。多くの内容は「ゼロから作るDeep Learning:オライリージャパン:斎藤 康毅 著」等の書籍で学習済なのですが、同じような内容であってもビデオ講座で説明されるとより簡単に理解できるように感じます。講座を受講した後には、明細書がすらすら書けますのでこれだけでも受講した価値があると感じます。
また、CNNと自然言語処理は以前から体系的に学習してみたいと思っていました。CNNと自然言語処理はCOURSERAの講座に含まれているため、このあたりが講座を選択する主な理由になりました。ちなみに、この講座は課金が1ヶ月毎になっているため、非常に始めやすくて助かります(UDACITYは一括課金)。
COURSERAの講座におけるコーディングの課題は非常に簡単です。ステップバイステップになっており、直前の説明を読めば書くべき内容はすぐに分かります。それでもデバッグによって数時間かかることもザラであり、この期間が意外に重要と感じます。初稿のコードはほとんどの場合動きませんので、デバッグが必要です。その過程でより深く考えることで人工知能の理解が自然に深まっていきます。講座を継続してみて、コードの内容は簡単であるものの、理解を深められるようによく考えられていることが分かってきました。
先日、全5講座のうちの最初(Neural Networks and Deep Learning)を修了したところです。現在CNNについて学習中です。YOLO(You Only Look Once)などの新しい技術も説明してもらえるようなので、しっかりと学習していきたいと思っているところです。
AIは人類にとって脅威なのでしょうか?
今さら?と思えますが、AIが人間の仕事を奪うという話は未だに頻繁に話題になりますので私も少し乗っかってみたいと思います。
有名なのは、野村総合研究所が発表したこれですね。弁理士の仕事の92.1%はAIに取って代わられるという予想もあるとか。
根拠を探ってみましたがウェブサイトからはたどり着くことができませんでした。また、分析に利用されたデータとして 労働政策研究・研修機構「職務構造に関する研究」が挙げられていましたが、この研究は、各職業に必要なスキルや知識のアンケートをとって集計したもののようです。この集計結果は、業務の具体的な内容を示しておらずAIで代替可能かどうかの議論に値する情報を全く含んでいないと思えるのですが、分析の元データは本当にこのデータなのでしょうか?
ウェブサイトに開示されていた情報だけでは発表の内容を深く分析できないので、この発表結果は気にしないことにしてここでは弁理士の業務の代替可能性を技術的に検討してみます。
まず、弁理士の業務を特許明細書作成業務に絞ります。弁理士の業務と言えばまずこれでしょう。先行技術文献の検索業務など他の業務もありますが、検索業務等に依拠している弁理士の数は少なく、弁理士の業務の代替可能性を考える際に特許明細書作成業務を分析することが必須と思えます。ちなみに、私自身は、検索業務のような作業系の業務はすぐにでもAIに代替されてほしいと思っています。
現在AIと呼ばれているモノで実現性のあるモノといえば機械学習でしょうか。例えば、ニューラルネットワークに特許明細書業務を学習させるとか、強化学習で良い明細書を書けるようにするとかが想定されるのでしょうか?無理としか思えません。機械学習を進めるためには正解が必要だからです。具体的に実現しようとすれば、何が正解なのか定義しなければなりません。例えば、発明者の書いた発明提案書を明細書に変換するニューラルネットワークを考えてみましょう。この例であれば、発明者の書いた発明提案書と理想的な明細書とを対応づけた教師データを使ってニューラルネットワークに学習させることになりますね。この時点で不可能としか思えません。ある入力情報に対応する理想的な明細書なんてモノは世の中に存在しませんし、既存のデータから正解を創ることはできません。
既存のデータ、例えば、発明提案書と出願済明細書とのセットを教師データとすれば学習は可能かもしれませんが、このセットは正解でしょうか。必ずしも正解ではなく、場合によっては品質が良くない明細書も多く存在するのではないでしょうか。こんな教師データを使って学習しても、意味のない学習しかできません。
特に請求項は、出願人の個別の事情や発明の内容に応じてカスタマイズされる必要があります。そんなことが可能な教師データがどこにあるのでしょうか?判例でしょうか?判例に挙げられた請求項が、正解だとは思えませんし、そもそも圧倒的に数が足りません。
上述のニューラルネットワークは私の勝手な予想であり、実際には別の理由で代替可能性が議論され得るのかもしれませんね。発明提案書を入力し、出願済明細書を出力する処理が可能であるという前提がそもそもファンタジーですし。例えば、汎用人工知能が完成すれば弁理士の業務をAIが実行することができるでしょうか?できるかもしれませんし、できないかもしれません。いずれにしても、汎用人工知能が具体化する道筋が見えていない現在においてその完成を予想し、しかも弁理士の業務が代替される可能性を予想するのは、ロジカルな話になり得るでしょうか。私にはタイムマシンが実現するか否かを予想するのと同程度の話にしか思えません。
弁理士の業務の代替性をまじめに考えるのであれば、少なくとも、どのようなデータを使って学習させるのか明らかにするとか、業務を代替可能にする技術的アプローチを具体化するとか、そのような議論が必要なのではないでしょうか。私自身は、正解のデータを用意できる業務であれば代替される可能性が高いと思いますが、正解のデータを用意できない業務が近い将来に代替されると思えないです。
年末に予定していたとおり、休み期間中にVoice Kit をいじってみました。
年末年始、我が家ではボードゲームがブームでした。「カタンの開拓者たち」というボードゲームなのですが、非常に完成度が高く子供も大人も夢中になって楽しむことができます。このゲームは、2つのサイコロを振り、出た数の和を使って進行していきます。このため、2つのサイコロを振って出た数の和が戦略上とても重要になります。うちの子供たちは、当初、2つのサイコロを振って出た数の和を確率で推定できるということを知らず、説明してもよくわからない様子でした。そこで、出た数の和を記録してみることにしてみました。ゲーム中にサイコロを振って出た数の和を全て記録していくのです。1ゲームではサイコロを振る回数がさほど多くなく、確率を正確に反映していないため、数ゲームにわたって記録を続けないと有意な結論を導けません。
ですが、毎回記録するのは面倒くさい。サイコロを振るたびにペンを使って数値を書き留めるだけなのですが、ゲーム中にこれを続けるのがすごく面倒くさい。
そこで、Voice Kitの登場です。
ゲーム中、サイコロを振るたびに2つのサイコロの数の和を発話し、発話回数を記録することにしました。Google Cloud Speechというサービスを使うと、マイクを介してraspberry PIが録音した音声をテキスト化してくれます。そこで、サイコロの数の和をテキスト化し、和の値を示すテキストである場合にその数値の発話回数を1プラスすれば、最終的に和の数がどの頻度で出現したか分かります。例えば、和が7の場合、「number seven」と発話し、7の発話回数を1プラスします。この処理を繰り返し、最後にその和を表示させるプログラムを作成しました。
結果、数値の記録がだいぶ楽になりました。音声入力でも若干面倒には思えましたが、それでもペンで記録するよりはずいぶんとましです。音声入力が終了した時点で電子データ化されているため集計も楽でした。
今回は、以上のような極々簡単な内容で音声認識技術を体験してみました。音声認識サービスが有用と思われる場面はたくさんあると思いますが、今回のように、あるタスク(ボードゲーム)を実行しながら別のタスク(サイコロの目の集計)も実行する場合、その一方を音声入力のみで実施可能にするサービスは非常に有用と思われます。
そして、このようなニーズはそこら中にありそうです。GoogleのサービスやVoice Kit を使えば、「こうなっていれば便利かも」というアイディアを実現するための装置を非常に簡単に試作し、有用性を判断したり、より本質的なニーズを発掘したりすることができます。従って、音声認識を行うためのAI技術などを持っていなくても音声認識を使った発明することが可能です。。。。
今後、音声認識に関する発明が増えるかもしれませんね。
おかげさまで最近大変多忙にしておりまして、ブログの更新が滞っていました。少なくとも年度末まではこのペースが続きそうですのでしっかり仕事を続けますが、合間を見つけてブログの更新も続けねばと思っているところです。
年末年始にはまとめてお休みがとれそうですので、人工知能関連技術の学習を再開するきっかけを作ろうと思っています。冬休みの宿題として。
みなさん、AIY Projectsってご存知でしょうか。
https://aiyprojects.withgoogle.com/
Do-it-yourself artificial intelligenceだそうです。
私は以前からこのプロジェクトに興味を持っており、AIを動かすコンピュータ(raspberry PI)とVoice Kitを注文してありました。最近になって届きましたので、冬休みに少しいじってみたいと思っています。
ウェブサイトによると「このプロジェクトのtook kitは我々や我々のコミュニティの問題を解決するために提供されている」とのことです。Pythonを扱える技術者なら、ささっとアプリケーションを作れそうです。誰でも安価に高度な技術を利用できるってすばらしいですね。
Voice Kitは自分で組み立てたスピーカー、マイク一体型の装置から入力された音声でGoogle Assistantを利用したり、音声をテキスト化したり、音声でLEDを点灯させたり、いろいろなことができるようです。要するに音声入力によるアプリケーションを作ることができるということですかね。
冬休みだけでは時間が足りないかもしれませんが、Voice Kitで遊びながら実際に開発を体験しつつ、音声認識技術を利用した特許についても考えていこうと思っています。
週末(7月15~17日)の間にブログを書こうと思っていたのですが、運悪く特許庁のJ-PlatPatがメンテのため使えず、書こうと思っていた記事に必要な情報を入手できない。他にも週末にJ-PlatPatを使ってやることがあったのですがそれもできない。ちょうど、有料の特許データベースの契約を検討中だったのですが、そちらが加速しそうな感じです。
気を取り直して、J-PlatPatが使えなくても書ける記事を急遽模索してみました。ちょっと安易ですが、日本の特許データベースがだめなら米国の特許データベースを使って書ける記事にします。
今回は、STAP細胞の米国特許について取りあげます。STAPというのは、刺激惹起性多能性獲得(Stimulus-Triggered Acquisition of Pluripotency)のことで、少し前に大いに話題になったものです。
あのときは論文の内容の信憑性が話題になりましたが、もちろん特許出願もなされており、米国や日本も含めて9か国に出願されているようです。STAP細胞についての米国特許出願(14/397080)の状況をUSPTOのPAIRで調べたところ、このような記録(重要なイベントのみ抜粋)となっていました。
10-24-2014 Transmittal of New Application
01-08-2015 Preliminary Amendment
07-06-2016 Non-Final Rejection
01-06-2017 Affidavit-traversing rejections or objections rule 132
01-06-2017 Applicant Arguments/Remarks Made in an Amendment
05-18-2017 Final Rejection
06-30-2017 Applicant Initiated Interview
最初の拒絶理由通知に応じて意見書と発明者(バカンティ氏)の宣誓供述書が提出されました。しかし、審査官の心証は覆らず、2017年5月18日にファイナルの拒絶理由通知が出されました。
最初とファイナルの拒絶理由通知で審査官が使用した根拠条文は以下のものです。
【35U.S.C.112】(a)The specification shall contain a written description of the invention, and of the manner and process of making and using it, in such full, clear, concise, and exact terms as to enable any person skilled in the art to which it pertains, or with which it is most nearly connected, to make and use the same, and shall set forth the best mode contemplated by the inventor or joint inventor of carrying out the invention.
【35U.S.C.101】Whoever invents or discovers any new and useful process, machine, manufacture, or composition of matter, or any new and useful improvement thereof, may obtain a patent therefor, subject to the conditions and requirements of this title.
【35U.S.C.102】A person shall be entitled to a patent unless
(b) the invention was patented or described in a printed publication in this or a foreign country or in public use or on sale in this country, more than one year prior to the date of the application for patent in the United States, or
審査官はSTAP細胞の論文が取り下げられたことや否定的な再現試験の結果を当然知っており、112条(明細書が実施可能要件を満足しない点)と101条(発明がうまく働かない結果、有用性が認められない点)について突いてきています。これだけ発明の再現性(反復可能性)について否定的な状況だと見過ごすわけにいかなかったのでしょう。こういう事件を担当する審査官は大変ですね。
ちなみに、私が担当した案件で一度だけ日本の審査官に『このような発明品は実在しないから発明が不明確であると』と指摘されたことがあります。出願人もまじめに出願しているのだから『実在しない』なんて失礼にも程があると憤りを感じましたが、証拠写真を提出して『本当にあるよ!』と反論して済ませました。バカンティ氏の宣誓供述書も概ね『STAP細胞は本当にあるよ!』という内容なんだと思いますが、簡単には信用してもらえないということのなでしょうか。
話をSTAP細胞の拒絶理由通知に戻すと、102条についてはiPS細胞の中山先生の特許(MEF細胞を毒素(toxin)に曝すことで多機能細胞が生成できるとの記載)が引用されています。ちなみに最後に行われたメインクレームの補正は以下の通りで、哺乳動物体細胞に与えるストレスの一つとして毒素(toxin)を含んでいます。
以上のようなファイナルの拒絶理由通知の後のイベントとして、ついこの前の6月30日に『Applicant Initiated Interview Summary (PTOL-413)』というステータスが記録されていました。このInterview Summaryを見てみると、以下のような記載となっていました。
Applicant’s representative discussed the retracted publication by the applicant’s and potential narrowing claims. The examiner agreed with that the narrowing claims might overcome the enablement rejection depending on how much the claims narrowed and what is in the specification.
電話インタビューの結果、クレームを減縮することにより拒絶理由が解消し得ることに審査官が同意しているようです。102条についてはクレーム減縮が有効であるように思います。しかし、112条と101条の拒絶理由の適否は、STAP細胞の再現性にかかっており、クレーム減縮で解決できるような質のものでないように思います。また、電話インタビューの記録にあるように、拒絶を克服できるか否かは『depending on・・・what is in the specification』となっています。いまさらニューマターを導入することなく、明細書の記載をどうにかできるのか疑問に思います。
どのようにクレーム減縮がなされるのか、本当にクレーム減縮で拒絶理由を解消できるのか非常に気になるところです。
google アシスタントを試してみました。
最近自分のスマートフォンでgoogle アシスタントが使えるようになりましたので、少し試してみました。
google アシスタントは、音声または文字によって質問を入力すると、google先生が回答を返してくれるプログラムです。スマートフォンの場合には音声入力を手軽に利用できますので、音声入力を使いながらgoogle アシスタントを試してみました。
質問を音声で入力してみたところ、ほぼ完璧に入力文を認識しました。もはや音声認識精度に驚く時代ではないのかもしれませんが、実際に試してみると、ものすごく高い精度にやっぱり驚いてしまいます(ただし、例外もありました)。
「日本の面積を教えて」、「特許って英語でなんていう?」などと言った質問には即座に完璧に答えてくれます。便利ですねえ。
では、特許業界のアシスタントとして使えるでしょうか?
「特許権の存続期間を教えて」、「特許権の無効理由を教えて」などいろいろ質問してみましたが、認識した文書をgoogle検索した結果が返ってきただけでした。さすがに無効理由から条文を教えてくれるとか、条文に規定された無効理由を教えてくれるなんてことはありませんでした。こんなことができる時代は来るのでしょうか。
いろいろ試していくうちに、興味深いことも分かってきました。google アシスタントが私のこと(私のスマートフォンのデータ)を知りすぎているため、音声認識や提示内容に無用なバイアスがかかってしまうことがあるようです。
例えば、私の名前を音声認識させようとしたのですが、何度やっても失敗しました。認識結果が妻の名前になってしまうのです。音は全く違うのですが。。。私のスマートフォンに私の名前よりも妻の名前の方が多く保存されていたからなのでしょうか?例えば、メールの宛先など。理由は定かではありませんが、この例のように、いつまでも期待した認識結果にたどり着かないことがありました。
さらに、自分の知識外のことを知るためにgoogle アシスタントに聞いているのに、自分が知っていて当然の情報を返してくることがありました。例えば、「AIで有名な人を教えて」という質問にジェフリーヒントンさんのことを書いたウェブサイトを返してきたので、続けて「ジェフリーヒントンさんの特許出願を教えて」と入力してみました。できればgoogle patentsの検索結果を出力してほしかったのですが、Wikipedia の次に私たちのウェブサイトのブログのページを提案してきました。私たちはスマートフォンでの表示が適正であるのか否かを定期的にチェックしますので、おそらくchromeに履歴が残っていたのでしょう。しかし、それらは私たちが熟知していることなので、むしろ提案不要なのです。自分の知識外のことを知るためにgoogle アシスタントに聞いているのですから。
google アシスタントは多くの場面で有用であり、試していてとても楽しかったですし、その多才ぶりに驚きました。今後も使いたいと思いますが、上述のように、一部においては改善が期待されるようです。google関連のサービスはものすごい速さで進歩しますので、いつの間にか改善してしまうかもしれません。定期的にウォッチしていこうと思います。