- Home
- Our vision
- Our values
- Members
- Access
- Blog
- Join us
- Contact
- Language
第1回のエントリはこちら
第1回のエントリでは、疑似開発したニューラルネットワークで明細書執筆者を高い精度で推定できたことを示しました。
開発過程では、以下の3パターンの入力データに基づいてニューラルネットワークの学習を行いました。
1.文書表現上の癖
2.論理展開上の癖
3.文書表現上の癖と、論理展開上の癖の双方
以下、それぞれのパターンについて具体的に述べていきます。
●「1.文書表現上の癖」
第1回のエントリで述べたパターンです。このパターンでは、学習前に各明細書について以下の11個の項目を数値化しました。
メインクレーム行数、メインクレーム文字数、サブクレーム平均行数、サブクレーム平均文字数、クレーム1行あたりの「、」の数、クレーム1行あたりの文字数
明細書1段落あたりの「、」の数、明細書1段落あたりの平均文字数、明細書1文あたりの「、」の数、明細書1文あたりの文字数、明細書全文の文字数
学習の詳細は以下の通りです。
・trainingデータ:11個の項目の数値と執筆者を対応づけた300件のデータ
・testデータ:11個の項目の数値と執筆者を対応づけた90件のデータ
・隠れ層:ノード数7の1層
・ミニバッチ:10~50程度
・最適化方法:確率的勾配降下法(stochastic gradient descent)
・イタレーション:50000回
trainingデータで以上の学習を行い、学習後のニューラルネットワークで90件のtestデータの執筆者を推定したところ、正解率は88%でした(図1)。
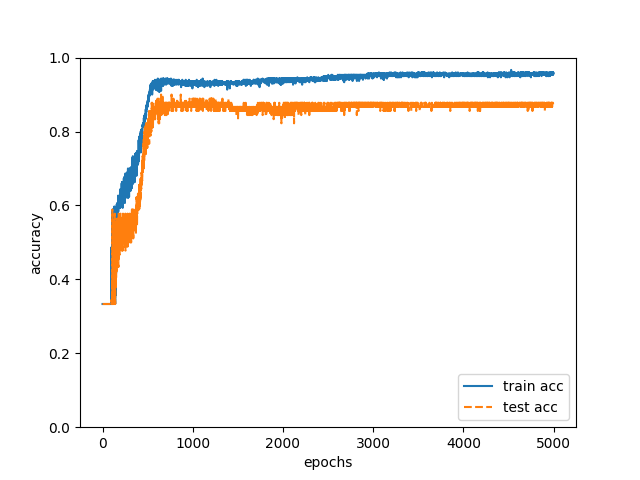
図1
●「2.論理展開上の癖」
このパターンでは、学習前に、各明細書について以下の7個の言葉の数を計測しました。
「しかし」、「なお」、「すなわち」、「また」、「さらに」、「ればよい」、「そして」
私自身は、文書を論理的に展開するために、「主張、解説、論証、例示」という順序で明細書内の文章を書くことが多いです。この順序で文章を書く場合、「解説」の前に「すなわち」が現れます。このような論理展開上の癖は、執筆者毎に異なるため、段落の最初の部分や最後の部分の単語を統計処理すれば執筆者が特定できると考えました。
学習の詳細は「1.文書表現上の癖」と同様です(ただし、隠れ層のノード数は5個)。
trainingデータで以上の学習を行い、学習後のニューラルネットワークで90件のtestデータの執筆者を推定したところ、正解率は79%でした(図2)。
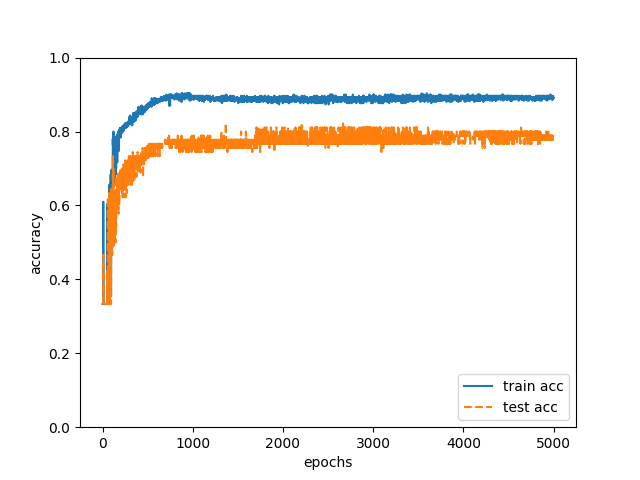
図2
以上のように、「1.文書表現上の癖」を入力データとした場合に88%、「2.論理展開上の癖」を入力データとした場合に79%の正解率が得られました。この結果は私の直感と違いましたので、少し戸惑いました。私自身で執筆者を推定する場合には、句読点の数等よりも執筆者特有の論理展開が現れるか否かに着目するからです。「2.論理展開上の癖」の方が、単に入力データの項目数が少ないために正解率に差が出ているだけかもしれませんが、それでも、執筆者の推定に「1.文書表現上の癖」が有効であることは分かりました。今回の成果に基づいて本気で特許出願をするのであれば「1.文書表現上の癖」を入力データとするという観点で権利化することは外せないでしょう。さらに、比較すると多少正解率が少なくなるものの、「2.論理展開上の癖」であっても79%もの正解率が得られるため、特許出願するならば「2.論理展開上の癖」を入力データとするという観点で出願することにもなるでしょう。
「1.文書表現上の癖」「2.論理展開上の癖」の一方を入力データにした場合に有意な正解率が得られたため、双方を入力データにするとより正確な推定が可能であると考えられます。そこで、
●「3.文書表現上の癖と、論理展開上の癖の双方」
についても学習を行いました。「1.文書表現上の癖」「2.論理展開上の癖」のそれぞれで利用した入力データを結合してtrainingデータとtestデータを作成しました。学習の詳細は「1.文書表現上の癖」と同様です(ただし、隠れ層のノードは11個)。trainingデータで以上の学習を行い、学習後のニューラルネットワークで90件のtestデータの執筆者を推定したところ、正解率は93%でした(図3)。90件のtestデータの中の84件は執筆者を正確に推定できたことになります。
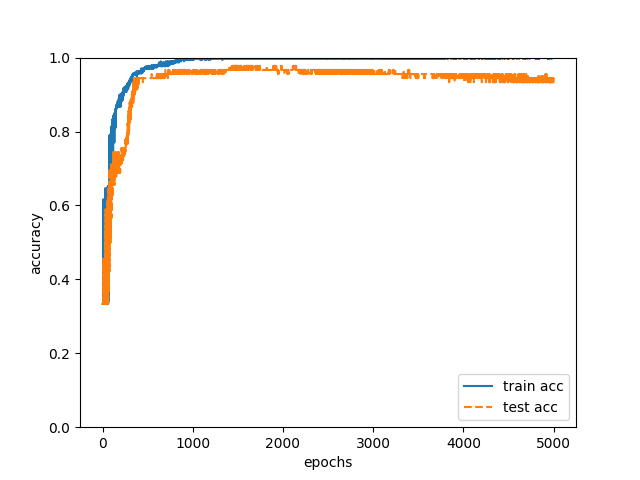
図3
明細書の執筆者を推定するための入力データとして「1.文書表現上の癖」「2.論理展開上の癖」「3.文書表現上の癖と、論理展開上の癖の双方」が有効であることは実証されました。一方、ニューラルネットワークの開発においては、ネットワークの構造を最適化することが必須になると考えられます。次回は、ネットワークの構造を変化させた結果を報告します。
