- Home
- Our vision
- Our values
- Members
- Access
- Blog
- Join us
- Contact
- Language
前回までの記事
プログラム著作物の争点(その1)
プログラム著作物の争点(その2)
前回(その2)では、プログラム著作物(著作権法10条1項10号)の著作権侵害が成立するか否かは、原告プログラムと被告プログラムとの間で『類似し、かつ、創作性がある部分』がどこであるかに依存する”ということまでお話ししました。
今回は『類似している部分』がどこにあればプログラムの著作権侵害が成立するのかについて「書類作成支援ツール事件(大阪地裁H14/7/25 H12(ワ)2452)」を挙げて話をします。
本件のプログラムは、表計算ソフトの入力シートにてユーザの入力を受け付け、入力された内容に基づいて高知県に提出するのに適式な申請書類を作成する機能を実現させるものです。プログラムの実体は表計算ソフトのマクロです。少し長いですが、まずは以下の判決文の抜粋をご覧下さい。
原告プログラムのコードと被告プログラムのコードを比較すると、原告プログラムでは、標準モジュール部分にプログラムが記載されているのに対し、被告プログラムでは、帳票を表すワークシート一枚一枚にマクロを割り当てて短いプログラムが記載されているという特徴があり、その結果、二つのソフトウエアの間には、プログラムの表現及び機能において、次の相違点があることが認められる。
ア 原告プログラムにはプログラムの冒頭に変数宣言が存在するが、被告プログラムは変数を全く使っていないため変数宣言がない。
イ 原告プログラムには、ファイルを開くときのプログラムにおいて、subプロシージャとして定義された”gamen” “deffile” “defpath”を実行するようになっているが、被告プログラムではsubプロシージャを実行するような記述はなされておらず、ファイルを開くドライブをCに固定し、フォルダも”syorui”に固定している。
・・(中略)・・
カ 原告プログラムにはエラーが出た場合の処理(「システムの異常の可能性があります。販売者まで連絡をして下さい。」などと画面に表示する。)を行うプログラムがある。被告プログラムは、エラーが出た場合には、”On Error Resume Next”、”On Error Go To 0″という宣言によりエラーをとばす処理をしている。
以上によれば、被告プログラムは、原告プログラムとは構造が著しく異なり、原告プログラムに設けられている機能の多くを有しておらず、プログラムの具体的な表現といえるコードにも類似する部分がないから、構造、機能、表現のいずれについてもプログラムとしての同一性があるとは認められない。したがって、被告プログラムは、原告プログラムを複製又は翻案したものとはいえない。
原告は、被告が原告プログラムをデッドコピーしたことの徴表として、被告プログラムの帳票部分の特徴を指摘するが、原告プログラムに含まれる帳票部分に著作物性を認められないことは前記のとおりであるから、帳票部分において被告プログラムが原告プログラムに酷似し、前者が後者をデッドコピーした徴表があるとしても、被告プログラムが原告プログラムを複製又は翻案したことを肯定する根拠とはならない。
要するに、この判決では、プログラムのソースコードが、原告プログラムと被告プログラムとの間で類似し、かつ、創作性がある部分となっていないとプログラム著作物の著作権侵害にはならないということが述べられています。
図3を用いて説明します。円が原告のプログラムの範囲を示し、そのうちグレーの部分が原告プログラムと被告プログラムとで類似している部分を示し、●が創作性のある部分を示しています。
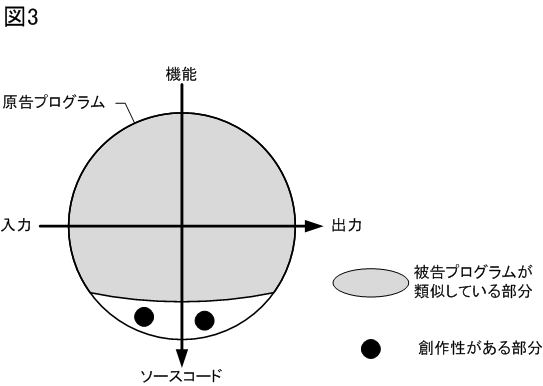 今回の事件では、表計算ソフト上でユーザが入力を行う入力シートがほぼ同一であり、最終的に出力される申請書類も同一でした。入力シートにおいて入力された内容に基づいて申請書類を生成する各工程における処理(機能)についてもほぼ同じであったはずです。そのため、図3に示すように、入力から出力までの工程の全体にわたる機能的な部分において広く類似していたと予想されます。
今回の事件では、表計算ソフト上でユーザが入力を行う入力シートがほぼ同一であり、最終的に出力される申請書類も同一でした。入力シートにおいて入力された内容に基づいて申請書類を生成する各工程における処理(機能)についてもほぼ同じであったはずです。そのため、図3に示すように、入力から出力までの工程の全体にわたる機能的な部分において広く類似していたと予想されます。
しかし、●で示すように、本判決において原告プログラムのうち創作性が認められたのはソースコードであり、そのソースコードについては類似性が認めらませんでした。そのため、この事件ではプログラム著作物の著作権侵害は否定されました。
ここで、著作物は、「思想又は感情を創作的に表現したものであって、文芸、学術、美術又は音楽の範囲に属するもの」(著作権法2条1項1号)です。ここだけを読むと、プログラムにおいて利用者が感得できるように表現される部分(おもにUI画面や最終出力結果)がマネされればプログラム著作物の著作権侵害となると思いがちですが、それだけでは著作権侵害にはならないため注意が必要です。前記の判決に記載されるように、プログラムの具体的な表現はあくまでもソースコードであり、著作権法が保護すべき価値はソースコードに存在するということなのです。かなりの部分で類似しているのにも拘わらず、原告には残念な結果に...
が、しかし、
今回の事件はこれだけでは終わりませんでした。なんと、著作権侵害にはあたらないけど損害賠償請求と差止請求が認められました。その理由を述べた判決部分は以下のとおりです。
民法709条にいう不法行為の成立要件としての権利侵害は、必ずしも厳密な法律上の具体的権利の侵害であることを要せず、法的保護に値する利益の侵害をもって足りるというべきである。他人のプログラムの著作物から、プログラムの表現として創作性を有する部分を除去し、誰が作成しても同一の表現とならざるを得ない帳票のみを抜き出してこれを複製し、もとのソフトウエアとは構造、機能、表現において同一性のないソフトウエアを製作することが、プログラムの著作物に対する複製権又は翻案権の侵害に当たるとはいえないことは、前記のとおりである。しかし、帳票部分も、高知県の制定書式により近い形式のワークシートを作るため、作成者がフォントやセル数についての試行錯誤を重ね、相当の労力及び費用をかけて作成したものであり、そのようにして作られた帳票部分をコピーして、作成者の販売地域と競合する地域で無償頒布する行為は、他人の労力及び資本投下により作成された商品の価値を低下させ、投下資本等の回収を困難ならしめるものであり、著しく不公正な手段を用いて他人の法的保護に値する営業活動上の利益を侵害するものとして、不法行為を構成するというべきである。したがって、被告は、原告に対し、本件不法行為により原告が被った損害を賠償する責任を免れない。
だそうです。なんとかして帳票部分(入力シート)について創作性を認めて図表の著作物(著作権法10条1項6号)の著作権侵害として処理できなかったのかと思います。
『が、しかし』以降は、このシリーズの本筋の話ではありません。
今回お伝えしたいことは、プログラムのソースコードが、原告プログラムと被告プログラムとの間で類似し、かつ、創作性がある部分となっていないとプログラム著作物の著作権侵害にはならないということです。
次回は、ソースコードの創作性と特許の進歩性との関係について判例を挙げて説明しようと思います。

第1回のエントリはこちら
第2回のエントリはこちら
第1回、第2回のエントリでは、ニューラルネットワークで明細書執筆者を高い精度で推定できたことを示しました。ただし、第1回、第2回では入力データを変化させるだけでした。ニューラルネットワークの開発では、ニューラルネットワークの構造も大きなテーマになると考えられます。ニューラルネットワークの構造としては、層の数やノードの数がまず検討対象となるでしょうが、よく知られているように、初期値を変化させるのも重要でしょうし、各種の最適化方法の利用(第1回、第2回は全てSGDでした)を検討しても良いと思います。
いろいろな手法が考えられますが、まずは層をよりdeepにすることが考えられます。今回の開発では項目数(入力ノードの数)が最大で18個しかありませんので、deepといってもたいした数の層は必要ないと予想できます。とりあえず、「3.文書表現上の癖と、論理展開上の癖の双方」のtrainingデータとtestデータを利用し、隠れ層を2層(ノードは13個、8個)として学習しました。結果は、98%の正解率。90件のtestデータについて2件不正解ということになります。非常に高い正解率です。本件については、ディープニューラルネットワークは必要ないと言えますね。そりゃそうですよね。入力ノードが少なすぎますから。ディープニューラルネットワークの開発を疑似体験するためにはサンプルが不適切でした。まあでも入力データが執筆者の推定に適したデータであったからここまで正解率が向上したとは言えるでしょうか。
当初は、自己符号化器などを利用しながら少しずつ正解率を向上させたいと思っていました。モダンな(といっても自己符号化器が話題になったのは10年前ですが)技術を学習したいと思っていましたから。また、単なるニューラルネットワークではなく、同一層においてあるノードの出力を他のノードに入力するなど、ネットワークの構造にも各種の工夫があり得ます。
しかし、ここまでの結果から判断すると、現在のサンプルではニューラルネットワークの構造や各種のテクニックの有用性を判断できるほどサンプル数がないと考えられます。これ以上の改善の余地はあるのかもしれませんが、仮に、正解率が100%になったとしても、ニューラルネットワークの構造の変更等が効果的であったのか偶然なのか、サンプル数が少なすぎて判断できません。そこで、自己符号化器などを利用した開発は、将来別の案件で試してみたいと思います(今のところ、word2vecやQ学習での開発を体験できれば良いなと考えています)。
さて、第1回~第3回までで、ニューラルネットワーク関連の開発過程を疑似体験しましたので、次回は開発過程で生じ得る発明の特許化について考えてみたいと思います。
第4回のエントリはこちら
第1回のエントリはこちら
第1回のエントリでは、疑似開発したニューラルネットワークで明細書執筆者を高い精度で推定できたことを示しました。
開発過程では、以下の3パターンの入力データに基づいてニューラルネットワークの学習を行いました。
1.文書表現上の癖
2.論理展開上の癖
3.文書表現上の癖と、論理展開上の癖の双方
以下、それぞれのパターンについて具体的に述べていきます。
●「1.文書表現上の癖」
第1回のエントリで述べたパターンです。このパターンでは、学習前に各明細書について以下の11個の項目を数値化しました。
メインクレーム行数、メインクレーム文字数、サブクレーム平均行数、サブクレーム平均文字数、クレーム1行あたりの「、」の数、クレーム1行あたりの文字数
明細書1段落あたりの「、」の数、明細書1段落あたりの平均文字数、明細書1文あたりの「、」の数、明細書1文あたりの文字数、明細書全文の文字数
学習の詳細は以下の通りです。
・trainingデータ:11個の項目の数値と執筆者を対応づけた300件のデータ
・testデータ:11個の項目の数値と執筆者を対応づけた90件のデータ
・隠れ層:ノード数7の1層
・ミニバッチ:10~50程度
・最適化方法:確率的勾配降下法(stochastic gradient descent)
・イタレーション:50000回
trainingデータで以上の学習を行い、学習後のニューラルネットワークで90件のtestデータの執筆者を推定したところ、正解率は88%でした(図1)。
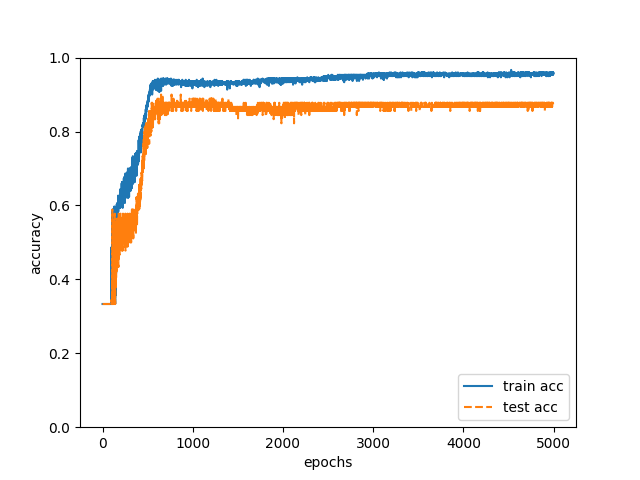
図1
●「2.論理展開上の癖」
このパターンでは、学習前に、各明細書について以下の7個の言葉の数を計測しました。
「しかし」、「なお」、「すなわち」、「また」、「さらに」、「ればよい」、「そして」
私自身は、文書を論理的に展開するために、「主張、解説、論証、例示」という順序で明細書内の文章を書くことが多いです。この順序で文章を書く場合、「解説」の前に「すなわち」が現れます。このような論理展開上の癖は、執筆者毎に異なるため、段落の最初の部分や最後の部分の単語を統計処理すれば執筆者が特定できると考えました。
学習の詳細は「1.文書表現上の癖」と同様です(ただし、隠れ層のノード数は5個)。
trainingデータで以上の学習を行い、学習後のニューラルネットワークで90件のtestデータの執筆者を推定したところ、正解率は79%でした(図2)。
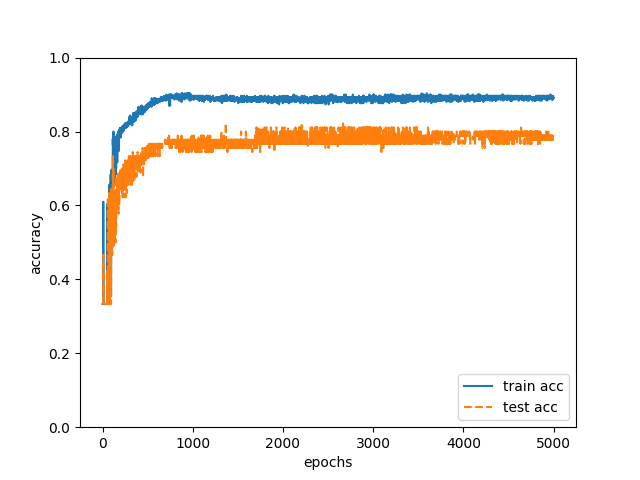
図2
以上のように、「1.文書表現上の癖」を入力データとした場合に88%、「2.論理展開上の癖」を入力データとした場合に79%の正解率が得られました。この結果は私の直感と違いましたので、少し戸惑いました。私自身で執筆者を推定する場合には、句読点の数等よりも執筆者特有の論理展開が現れるか否かに着目するからです。「2.論理展開上の癖」の方が、単に入力データの項目数が少ないために正解率に差が出ているだけかもしれませんが、それでも、執筆者の推定に「1.文書表現上の癖」が有効であることは分かりました。今回の成果に基づいて本気で特許出願をするのであれば「1.文書表現上の癖」を入力データとするという観点で権利化することは外せないでしょう。さらに、比較すると多少正解率が少なくなるものの、「2.論理展開上の癖」であっても79%もの正解率が得られるため、特許出願するならば「2.論理展開上の癖」を入力データとするという観点で出願することにもなるでしょう。
「1.文書表現上の癖」「2.論理展開上の癖」の一方を入力データにした場合に有意な正解率が得られたため、双方を入力データにするとより正確な推定が可能であると考えられます。そこで、
●「3.文書表現上の癖と、論理展開上の癖の双方」
についても学習を行いました。「1.文書表現上の癖」「2.論理展開上の癖」のそれぞれで利用した入力データを結合してtrainingデータとtestデータを作成しました。学習の詳細は「1.文書表現上の癖」と同様です(ただし、隠れ層のノードは11個)。trainingデータで以上の学習を行い、学習後のニューラルネットワークで90件のtestデータの執筆者を推定したところ、正解率は93%でした(図3)。90件のtestデータの中の84件は執筆者を正確に推定できたことになります。
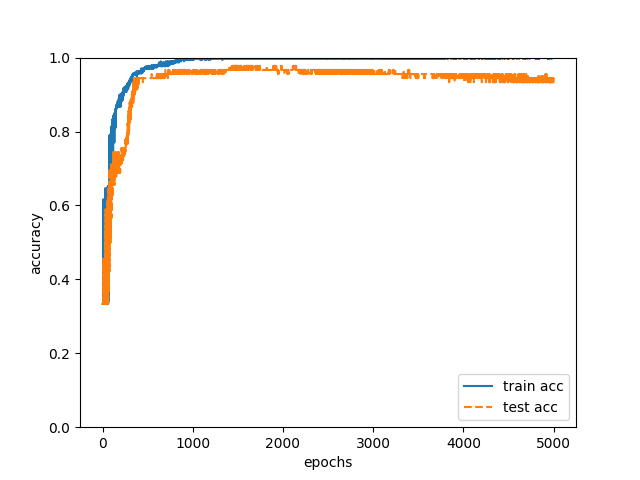
図3
明細書の執筆者を推定するための入力データとして「1.文書表現上の癖」「2.論理展開上の癖」「3.文書表現上の癖と、論理展開上の癖の双方」が有効であることは実証されました。一方、ニューラルネットワークの開発においては、ネットワークの構造を最適化することが必須になると考えられます。次回は、ネットワークの構造を変化させた結果を報告します。
モノ、コトのコストがものすごい速さで低下しているように感じます。私が学生の頃は、学習のためにまず良い本を探すところから始めましたが、良い本に巡り会うまでにやたらと時間コストがかかりました。今では検索すればすぐに良い本を見つけられますし、本を購入しなくてもweb上で良い情報を読むことが可能ですね(google先生ありがとう)。大学レベルの講義も多くのMOOCで無料ですので意欲のある人はいくらでも学習できますね。最近、私は人工知能関連技術の学習に注力していますが、ネットを利用することで極めて低コストで効率的に学習できたように感じます。ネット関連技術に感謝したい。
私は弁理士ですので発明の権利化に興味がありますが、私自身は、一貫して技術を深く理解した後に権利化の戦略を考えるという立場で仕事をしています。そこで、人工知能関連の技術においてもまず技術を深く理解することが自分にとって極めて重要と考えています。深い理解のためには自ら開発するのが一番と考え、特定の目的を達成する技術の開発を疑似体験してみました。開発の疑似体験を通じて、人工知能関連技術の特許化戦略を検討することを目標にしています。まだまだ学習は継続しますが、とりあえず一区切りしましたので、何回かに分けて学習成果を記録しておこうと思います。
開発の概要は以下の通りです。
・目標:特許明細書の特徴から特許明細書の執筆者を特定する人工知能の開発
・利用技術:ニューラルネットワーク
要するに、ニューラルネットワークについて私が学習するために、身近な特許明細書を題材にしたと言うことです。採用したニューラルネットワークは以下の図1の通りです。
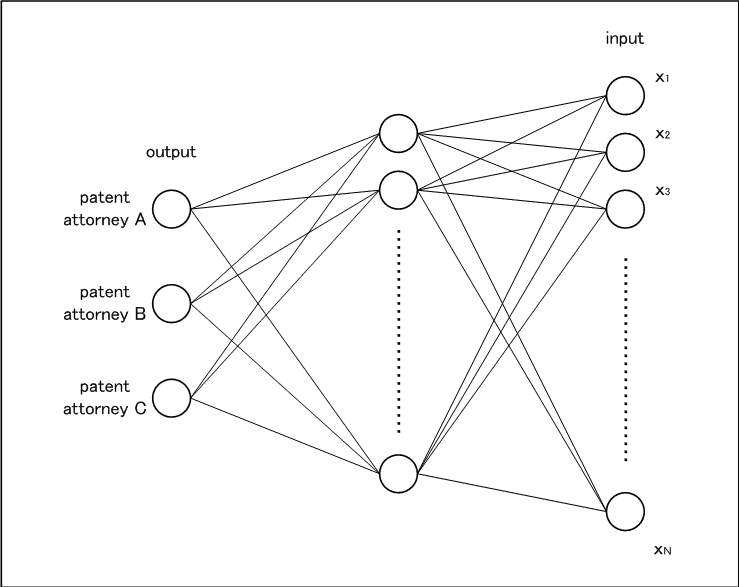
図1
弊所には弁理士が3人おります。各弁理士が執筆した明細書の公開公報を比べると、それぞれの明細書にそれぞれのスタイルがあるように思えます。そこで、各弁理士の明細書の解析結果を入力データとし、弁理士A~Cに対応する3個のノードを出力データとすれば、明細書の特徴を入力し、執筆者を出力するニューラルネットワークを開発できると考えました。
出力ノードは各弁理士に対応させる(ノードの出力の最大値が執筆者の推定結果となる)と決まりました。あとは、1.入力データの決定、2.適切なニューラルネットワークの選定、を行えば、ある程度の出力が得られるニューラルネットワークを開発できそうです。
まずは1.入力データの決定です。とりあえず、ニューラルネットワークは図1に示すように1層の隠れ層を有する構成とし、入力ノードの数と出力ノードの数との中間程度の数で隠れ層のノードを構成しておきます。
さて、入力データは3パターン考えました。
1.文書表現上の癖
2.論理展開上の癖
3.文書表現上の癖と、論理展開上の癖の双方
いずれの特徴も、技術分野に大きく依存せず、全ての明細書に多かれ少なかれ現れるため、これらの特徴を数値化できれば執筆者と1対1に対応する入力データを作成できるのではないかと推定したわけです。
以上のような開発方針が決定したら、次は実践です。
まずは各弁理士の明細書を130件ずつ集めました。これらをテキストデータ化し、テキストデータを複数の観点で統計処理し、得られた複数の値を複数のノードへの入力データとします。このような前処理により、弁理士A~Cのいずれかと複数のノードへの入力データとが対応づけられた教師データを390件生成しました。
今回はこの中の300件をtrainingデータ、90件をtestデータとしました。教師データの中から「1.文書表現上の癖」を表すデータを使って50000回のイタレーションをおこなったところ、以下の図2のようにtrainingデータの正解率(train acc)が96%、testデータの正解率(test acc)が88%になりました。。。。
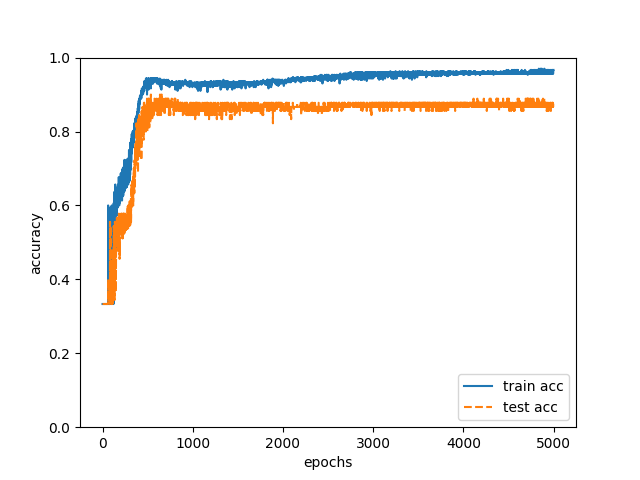
図2
88%。びっくりです。正直うまくいきすぎではないでしょうか。明らかに過学習しているなど、向上の余地はまだまだありますが。普段、各弁理士の執筆原稿を読んでいて、「この明細書は弁理士Aが書いたようだ。」などの推定はできますが、たかが表層的な特徴だけで約90%の確率で執筆者を当てられるなんて。。。意外なことに執筆者の癖は明細書でかなり明らかに現れているのですね。人間にはこの精度で執筆者を推定するなんて到底不可能ですよね。ニューラルネットワークのポテンシャルを実感できました。
さて、長くなってしまいましたので、「1.文書表現上の癖」の具体的な解析、「2.論理展開上の癖」「3.文書表現上の癖と、論理展開上の癖の双方」の具体的な解析については次回に致します。
第2回のエントリはこちら
第3回のエントリはこちら
第4回のエントリはこちら
・参考文献
「ゼロから作るDeepLearning」オライリージャパン 斎藤康毅 著
いくつか読んだ中では解説が大変わかりやすかったです。この本がなければ今回の成果は得られなかったと思います。
「言語研究のためのプログラミング入門」開拓社 淺尾仁彦・李 在鎬 著
明細書のテキストから特徴を抽出するプログラムを作成する際に参考にさせて頂きました。
「Deep Learning」https://www.udacity.com/course/deep-learning–ud730
DeepLearningを自己学習するきっかけを与えてくれた講座です。