- Home
- Our vision
- Our values
- Members
- Access
- Blog
- Join us
- Contact
- Language
人工知能関連技術について出願動向を調べました。一部をメモしておきたいと思います。
以下の棒グラフは(公開年ANDキーワード)で得られたデータの統計です。検索にはJ-PlatPatを使用しました。例えば、公報全文に自己符号化器が含まれる2001年公開の出願は、(公開日:2001年1月1日~12月31日)AND(公報全文に含まれるキーワード:自己符号化器ORオートエンコーダー)として集計しました。2017年は4月17日までのデータになります。特定のキーワードを含む明細書の年毎の公開件数(左縦軸)が棒グラフで示されています。また、日本特許庁全体での年毎の公開件数(右縦軸)が折れ線グラフで示されています。

【図1】
図1は、人工知能というキーワードが含まれる公報を公開年で集計した結果です。人工知能というキーワードを含む出願は2002年頃から増え始めて年200件に達した後、2007年頃に減少に転じ、2011年頃に再び増加して近年は年200件レベルで推移しています。2016年は少し減っていますが2017年は4月の段階で100件を超えていますから直近では増加傾向であるように思えます。2003年以降の底は2009年ですから、サブプライム問題に起因する不況の影響を受けて減ったと推定されます。
しかし、いずれにしても公開件数が多くて200件規模というのは、ブームと言われている状況からして少なすぎるように思えます。多くの企業がしのぎを削っている昨今の状況を全く反映していないように思えます。
そこで、キーワードを変えて再検索してみました。
図2は、機械学習というキーワードが含まれる公報を公開年で集計した結果です。

【図2】
ご覧の通り、きれいに「ブーム」といえるデータになりました。国内公開件数の減少に全く影響されずに機械学習というキーワードが含まれる公報の公開数が増加しているように見えます。
「人工知能」という漠然とした記述よりも、「機械学習」というより具体的な技術が明細書で述べられ、その件数が急激に増加しているという事実は、技術の解説書であるべき特許明細書の特性を反映しているのかもしれません。ニュース等では「機械学習」より「人工知能」の方がよく使われるのと好対照ですね(グーグル検索でも「人工知能」でのヒットの方が「機械学習」でのヒットより圧倒的に多いです)。むろん、ブームに乗じて「機械学習で行ってもよい」という程度の記述が含めてある明細書も存在するでしょうが、そうであっても図2に示す激増は、近年のようにブームと言われる状況が特許業界でも起こっていることを示しているように思えます。各社で熾烈な争いが行われていると推測されます。
次に、個人的に興味がある機械学習関連の要素技術について調べてみました。図3は、word2vec、自己符号化器(オートエンコーダ)、強化学習というキーワードが含まれる公報を公開年で集計した結果です。

【図3】
全ての要素技術において公開件数は少ないのですが、自己符号化器については、あまりの少なさにびっくりしました。明細書で公開するような内容ではないと言うことでしょうか?私が以前読んだ本では、自己符号化器が、現在の人工知能ブームの一要因としてあげられていたため、もっと出願されているだろうと推測していました。ちなみに米国ではautoencoderというキーワードを含む明細書で、比較にならないほど多くの出願がなされています。
word2vecは最近(2014年頃?)提唱された技術なので、まだ出願は少ないと推測されます。
強化学習は、少ないながらもある程度の数の出願で触れられているようです。こちらも、日本全体の公開件数の減少に反して件数が増加または維持していると言えるでしょうか。2017年は突出して多いため、今後延びていくかもしれません。
私自身は機械学習関連の技術で強化学習に極めて大きい関心を持っています。強化学習は、教師なし学習で自動的に最適化してくれる技術であるため応用範囲が非常に広く、出遅れているといわれる日本企業や、規模の比較的小さな企業にもまだチャンスがあるのではないかと期待しています。
機械学習を含む明細書を出願している出願人には、出願件数上位の常連ではない出願人が含まれていました。しかも、直近で非常に多くの出願をしており、直近のシェアが突出している出願人が存在します。この企業の製品を見ると出願数を激増させる戦略が極めて妥当のように思えます。むしろ、同業他社は何をしているのだろうと思うぐらいです。
調べてみると他にも各種企業の様々な戦略が垣間見られて非常に興味深かったです。機会があれば、より深掘りしてみようと思います。

IOT関連技術、AI関連技術に関する特許出願の審査ハンドブックに事例が追加されたようです。
特許庁ウェブサイトのこのページの一番下に参考資料としてまとめられています。
AI関連では、
・事例3-2:リンゴの糖度データの予測に機械学習を適用した事例
・事例2-13:音声対話システムの対話シナリオのデータ構造
・事例2-14:宿泊施設の評判を分析するための学習済みモデル
・事例31:車載装置及びサーバを有する学習システム
・事例32:製造ラインの品質管理プログラム
が追加されたようです。
・事例3-2
この事例は、「所定期間分のリンゴの糖度データ及び過去・将来の気象条件データを入力として、将来の出荷時のリンゴの糖度データを予測して出力する」特徴を持つ請求項が「発明」に該当する例です。この請求項の例では請求項に人工知能関連技術は明示されておらず、従来の請求項のスタイルと何ら変わりありません。ソフトウェア関連の審査基準からして明らかに発明に該当すると言えるでしょう。本事例が追加された意義は、予測が機械学習であるという点にあるようです。請求項に機械学習は現れないのですが、明細書の課題解決手段には、「予測のための分析が機械学習で行われる」ことと、「機械学習の実現法」と、が開示されていることが想定されています。
機械学習を利用した予測について請求項を作成する際には、多くの場合、この請求項のスタイルが採用されると思います。以前のブログにも書いたように、多くの人工知能関連技術において、入力データを決定することが発明であり目的を達成するための重要なファクターといえますし、機械学習には技術的な特徴が現れない場合が多いと考えるからです。
なお、ここで紹介した事例3-2は発明該当性を論じるための事例であるため、明細書内の記述の妥当性について特許庁は何も述べていないことに注意が必要です。実際に特許出願をする際には、例示された明細書の開示を超える内容が当然に必要になると考えます。
例えば、明細書の開示例として機械学習の進め方が示されていますが、実際に特許出願をする場合にはより詳細に機械学習について開示すべきと考えられます。また、予測を行うための開示が機械学習のみであると、過度の一般化に該当するおそれもありますので、機械学習以外の予測法があり得るのか否か、機械学習以外の予測法が出願人にとって有用であるのか否か等を検討し、必要に応じて機械学習以外の予測法を明細書に書くべきと考えます。
・事例2-13、事例31、事例32
事例2-13は、音声対話システムで利用される対話シナリオのデータ構造としての請求項が「発明」に該当する例です。
事例31は、車載装置で行う画像認識のパラメータを、サーバ内での機械学習で改善する請求項の進歩性を否定する例です。
事例32は、製造ラインの品質管理を行うために、サーバ内で検査結果と製造条件に基づいて機械学習を行う請求項の進歩性を否定する例です。
これら例では、実施形態として人工知能や機械学習が使用されていますが、一読したところ、人工知能関連技術であることが発明該当性や進歩性の結論に影響するものではないようで、新たな気づきは得られませんでした。単に人工知能関連技術の事例を追加したという位置づけでしょうか。近日中に、特許庁審査官の方が追加事例を解説する研修会がありますので、この事例の位置づけを確認してこようと思います。
・事例2-14
この事例は、学習済モデルという請求項が「発明」に該当することを示す例です。非常に有用な事例と思います。今のところ、特許庁は、学習済モデルというカテゴリーの請求項が「発明」に該当すると考えているようです。裁判所がどう考えるかは分からないものの、しばらくの間、学習済モデルという請求項がカテゴリーの不備で拒絶される心配はないため、出願戦略の選択肢が増えますね。この事例がなければ学習済モデルではなくプログラムとして請求項を作成したかもしれません。
さらに、この事例ではニューラルネットワークの構造を特徴として捉えて学習済モデルの請求項を作成しています。学習によって変化し得る重み付け係数も請求項に登場しますが、入出力の関係を示唆するほど詳細に重み付け係数の特徴が請求項で規定されているわけではありません。ニューラルネットワークの構造の特徴を記述するために必要な程度に請求項で重み付け係数が規定されています。これらのことから、少なくとも、特許庁はニューラルネットワークの構造が「発明」に該当すると考えているようです。今後、人工知能関連技術を出願し得る出願人は、ニューラルネットワークの構造に新規性や進歩性があるか否かを常に意識する必要がありそうです。むろん、ニューラルネットワークの構造を出願することが出願人の出願戦略上有意であるか否かは常に検討する必要があります。
以上が今回追加された事例でした。追加された事例においては、ニューラルネットワーク、サポートベクターマシンが登場しますが、他の技術、例えば、強化学習についても追加してあれば良かったと思います(強化学習は、人工知能関連技術で重要な分野になるのではないかと個人的に感じています)。今後の追加に期待しましょう。
詳細はこちらです。
この勉強会は主催者の方が運営しているウェブサイトのアクセスログをニューラルネットワークで学習し、アクセスログの特定のパラメータに基づいて、ウェブサイトからの離脱率を予測するという内容でした。
勉強会はハンズオンと呼ばれる形式でした。私はハンズオンの勉強会に初めて参加しましたが、ハンズオンは、自分自身でコーディングをしながらみんなで勉強するといった形式の勉強会だそうで、主催者の方をはじめ、詳しい方が多く参加されているようです。事前に予習し、積極的に参加するほど得られる成果は大きくなりそうです。
当日は、ハンズオンの他に3人の方が発表されました。
1.超解像関連の技術
2.TensorFlowで写真をゴッホ風の絵に変換
3.人工知能とデザインについて
という内容でした。
1.の超解像技術は、例えば、低解像度の画像から高解像度の画像を生成するような技術で、低解像度の画像を入力、高解像度の画像を出力としたCNNを学習すると、低解像度画像の高解像度化をすることができるとのことでした。ちょっと前にgoogleのニュースなどが話題になりましたが、それに類する技術のようです。そのときはどんな魔法?と思いましたが、技術的な説明を聞いてコンセプトはつかめたように思えました。私の知識不足で理解できなかったことも多かったのですが、論文等も紹介して頂いたので機会があれば勉強したいと思います。
制御系の仕事をしていると画像処理関係の特許技術が関連してくることも多いため、覚えておいて損はないように思えました。
2.も以前話題になりました。そのときはどうするのかと思いましたが、この話も技術説明を聞いてコンセプトは理解できましたように思えました。元画像と生成画像のとの差分と、画風画像の特徴量と出力画像の特徴量の分布の差分との和に基づいて学習するのだとか。うまいこと考えますねえ。こちらも画像処理関係の技術であるため、機会があればもう少し勉強しておこうと思います。
3.はデザインの話でした。懇親会で講師の方のお話を伺いましたが、ウェブサイトでのユーザーの行動解析によって商品購入を動機づけるレコメンドをするなど、現実のビジネスにインパクトを与えるアイディアをお持ちのようでした。人工知能はまだ話題先行のように思えますので、実際にビジネスに役立つアプリケーションを考えるのはとても大事ですよね。
ハンズオン、発表のいずれも私にとって刺激になりました。この勉強会は無料で開催されており、私たちはとても気軽に参加できますが、主催者の方々が無料で企画、運営するのはとても大変のように思えます。スポンサー企業様と主催者の方々に感謝です。今後も機会があれば参加したいと思います。
Tensor Flowのロゴ(例えばこのリンク)を見るといつも弁理士の役目を思い出します。このロゴはある方向から見るとT、別の方向から見るとFに見えるのですが、私は弁理士としていつもこういうスタンスで打ち合わせに臨まなきゃいかんと思っています。発明は見方を変えると全く違う姿になるぞと。。。
さて、日本の特許業界は繁忙期なので今回は小ネタです。
Tensor Flow。人工知能に興味のある方なら一度は耳にしたことがあると思います。実際に触ったことがある方も多いかもしれません。オープンソース化から1年ちょっと経過したようです。Tensor Flowに限らず、人工知能開発のための各種のライブラリが無料で公開されています。私は、Tensor Flow公開のニュースを聞くまで、このようなライブラリの無料公開が行われていることを知りませんでしたので、ニュースを聞いてちょっとした衝撃を受けました。Tensor Flowを使えば、素人(例えば私)でもアイディアと少しのプログラミング知識だけで、身近な問題を解決する技術を開発することができるのではないか?
ちょっと前まで、技術開発は専門知識を身につけた人材が開発環境の整った開発部に属することで初めて実現される、ある種の特権のようなものであったと思うのです。ですが、誰でも無料でライブラリを使えるならば、人工知能開発の少なくとも一部についての障壁は存在せず、誰でも開発者になれるように思えます。ソースデータをネットで収集し、Tensor Flowを使って機械学習を行えば、結構いろいろできるように思います。
実際、ネット上には「Tensor Flowで○○をやってみた。」といった内容の記事がたくさんアップされています。開発の障壁が下がった世界。一般人としてはとても良い世界のように思えます。ちょっとしたアイディアから意味のあるものをつくり出すことができる可能性があるわけですから。
一方、特許業界人としてその世界を見ると、かなり大変な状況なのではないかと思います。人工知能関連技術は他の技術と比較して、進歩性ありとされる技術のレベルが極めて速い速度で上がっていくように思えるからです。専門的な知識を持った開発者が自社の設備を使って開発を進める一方、専門的な知識を持っていない人でも自分のアイディアをちょっと試してみることができる。そして、ある程度の成果が得られた場合に、それをネットで公開する人も多い。それって進歩性判定の基礎となる公知文献が、極めて速い速度で増えていくことになるのでは?少なくとも、自動車のエンジン開発等、特殊な環境が必須になる一般の分野と比較して遥かに進歩性のレベルが上昇しやすいように思えます。大変な時代になってしまったと思います。特許業界人としては。人工知能関連技術を開発し、特許化する意志のある企業はものすごい速さで出願していく必要があるように思えます。
先日、海外企業(特に米国企業、中国企業)に比べて日本企業による人工知能関連の出願が遅れているというニュースが報じられていました。日本企業もがんばってほしいなあ~。
第1回のエントリはこちら
第2回のエントリはこちら
第3回のエントリはこちら
ニューラルネットワークに関連した開発においては、
1.入力データ、出力データの選定
2.ニューラルネットワークの構造決定
以上、2つのステージでたくさん発明がうまれそうです。
1.においては、目的を達成するためにどのような入力(または出力)とすべきか。これを決定すること自体が重要な発明と言えます。今回の開発では、「文書表現上の癖」や「論理展開上の癖」で執筆者を高精度に推定可能であると検証できたこと自体が発明と言えます。
最近はやりのディープニューラルネットワークであれば、どのような入力データが目的達成のために重要であるのか考えることなく、多数のデータを入力してディープニューラルネットワークによる学習を進めることで有用な結果が得られる可能性があります。
しかし、そうであっても、目的の達成に大きく寄与する入力データが多数の入力データの中のどれなのかを特定することが重要であると私は考えます。特許請求項は必須の要素のみを書くべきだからです。
必須の入力データAを特定できた場合の権利化戦略としては、種々の戦略が考えられます。ここではいくつかピックアップして書きたいと思います。
●まず、学習済のデータで推定を行う装置を以下のような請求項として表現した場合の戦略をいくつか挙げたいと思います。
「入力データAを取得する取得部と、
機械学習済の情報に基づいて前記入力データAを出力データBに変換する変換部と、
出力データBに基づいて○○を推定する推定部と、を備えるC装置。」
・入力データA(場合によっては出力データBも)が特徴であり、機械学習の過程は特徴としない。
第1回~第3回のエントリで体験したように、入力データを決定することが発明であり、目的を達成するための重要なファクターといえます。また、機械学習を進めるための具体的な技術は汎用的な技術で充分というケースは多いと考えられます(第1回~第3回のエントリで示した例もこれに該当するように思えます)。
・学習済のデータで推定を行い、出荷後には学習しない装置においては、機械学習を行う学習部を構成要件に含めないような請求項にすることが重要になると考えられます。学習部が構成要件に含まれると、出荷前に学習し、出荷後に学習しない装置を直接侵害で差し止めること等が不可能になります。
・ただし、「機械学習済の情報に基づいて」という文言で不明瞭とならないように請求項または明細書で対策をする必要があるでしょう。機械学習を進めるための具体的な技術が汎用的な場合は、汎用的であることを明細書で説明し、発明の特徴でないならばそのことを明細書で説明して実施可能要件を充足するようにしておくべきです。
・機械学習後のパラメータ、例えば、重み係数やバイアス等は、機械学習によって作成されるため、プロダクトバイプロセスの審査基準に適合する内容になるように明細書を書いておくと好ましいと考えます。
・発明の特徴は入力データAにあるため、入力データの特徴を上位概念から下位概念に展開するのが好ましいと考えます。第1回~第3回のエントリでの例であれば、句読点の統計、接続詞の統計、文末表現の統計など、切り口はたくさんありそうです。
●次に、学習を行うことが可能な装置を以下のような請求項として表現した場合の戦略をいくつか挙げたいと思います。
「サンプル入力データaと正解データbの組に基づいて前記サンプル入力データaを前記正解データbに変換するパラメータを機械学習する学習部と、
入力データAを取得する取得部と、
前記パラメータに基づいて入力データAを出力データBに変換する変換部と、を備えるD装置。」
・ユーザーが学習と変換(入力データAの出力データBへの変換)を実施できる製品が販売されるのであれば、このクレームが有効でしょう。
・学習部を備える学習装置(取得部と変換部を備えていない装置)という請求項も検討の価値があります。
・サンプル入力データaと正解データbの組は必須の組のみを独立請求項に書き込み、開発過程で検討した他の組(例えば、正解率の向上に寄与したが、最も重要ではないような組)は従属請求項で展開すると良いと考えられます。
・利用者が装置に学習させるのであれば、方法の請求項も有効と考えられます。
●最後にニューラルネットワークの構造ですが、ニューラルネットワークの構造が新規であり、かつ、進歩性があれば特許はとれると考えられます。しかし、この場合は慎重に請求項を作成する必要があると考えられます。ニューラルネットワークの構造を特徴とした請求項が権利化された場合であっても、第三者の被疑製品がその請求項を利用していることを立証することが困難である場合が多いからです。
ニューラルネットワークの構造は外部から見てブラックボックスになる場合が多いと予想されるため、ニューラルネットワークの構造自体を特許にしても有効ではない場合は多いと考えられます。第三者の被疑製品がその請求項を利用していることを立証することが事実上不可能であれば、侵害品対策のために出願しても意味がありません。他の事情(例えば、遅かれ早かれ学会で発表してしまうなど)がなければ、出願の可否から検討すべきと考えます。
・ニューラルネットワークの構造で特許を取る必要があるならば、当該ニューラルネットワークの構造を利用する装置を解析した場合に、観測できる特徴を見つける必要があると考えます。特許出願前の打ち合わせでは、観測できる特徴を見つける作業を行う必要があります。発明者様に特徴を見つけるための解析等をお願いすることも多くなるように思われます。
なお、ニューラルネットワークの構造ではありませんが、機械学習で最適化されたパラメータを出願するのは有効と考えられます。例えば、機能材料の組成や材料作成の際の温度、圧力等の最適数値範囲を機械学習で特定し、当該数値範囲を請求項とすることが考えられます。
この場合、数値範囲内の実測結果と数値範囲の境界での実測結果を明細書に記述することが通常の実務ですが、機械学習によって数値範囲を導出した過程を明細書に記述することで明細書の記載要件(実施可能要件等)を充足することは可能でしょうか?
機械学習によって数値範囲が得られ、その範囲での効果が論理的であれば、機械学習の過程を示すことで特定の数値範囲の発明を実施可能に明細書が記述されていることに間違いはなく、記載要件が充足するケースが出てきても良いと私個人は感じます。審査官、裁判官がどのように判断するのか今のところ不明ですが、興味深いトピックのように思えます。
第1回のエントリはこちら
第2回のエントリはこちら
第1回、第2回のエントリでは、ニューラルネットワークで明細書執筆者を高い精度で推定できたことを示しました。ただし、第1回、第2回では入力データを変化させるだけでした。ニューラルネットワークの開発では、ニューラルネットワークの構造も大きなテーマになると考えられます。ニューラルネットワークの構造としては、層の数やノードの数がまず検討対象となるでしょうが、よく知られているように、初期値を変化させるのも重要でしょうし、各種の最適化方法の利用(第1回、第2回は全てSGDでした)を検討しても良いと思います。
いろいろな手法が考えられますが、まずは層をよりdeepにすることが考えられます。今回の開発では項目数(入力ノードの数)が最大で18個しかありませんので、deepといってもたいした数の層は必要ないと予想できます。とりあえず、「3.文書表現上の癖と、論理展開上の癖の双方」のtrainingデータとtestデータを利用し、隠れ層を2層(ノードは13個、8個)として学習しました。結果は、98%の正解率。90件のtestデータについて2件不正解ということになります。非常に高い正解率です。本件については、ディープニューラルネットワークは必要ないと言えますね。そりゃそうですよね。入力ノードが少なすぎますから。ディープニューラルネットワークの開発を疑似体験するためにはサンプルが不適切でした。まあでも入力データが執筆者の推定に適したデータであったからここまで正解率が向上したとは言えるでしょうか。
当初は、自己符号化器などを利用しながら少しずつ正解率を向上させたいと思っていました。モダンな(といっても自己符号化器が話題になったのは10年前ですが)技術を学習したいと思っていましたから。また、単なるニューラルネットワークではなく、同一層においてあるノードの出力を他のノードに入力するなど、ネットワークの構造にも各種の工夫があり得ます。
しかし、ここまでの結果から判断すると、現在のサンプルではニューラルネットワークの構造や各種のテクニックの有用性を判断できるほどサンプル数がないと考えられます。これ以上の改善の余地はあるのかもしれませんが、仮に、正解率が100%になったとしても、ニューラルネットワークの構造の変更等が効果的であったのか偶然なのか、サンプル数が少なすぎて判断できません。そこで、自己符号化器などを利用した開発は、将来別の案件で試してみたいと思います(今のところ、word2vecやQ学習での開発を体験できれば良いなと考えています)。
さて、第1回~第3回までで、ニューラルネットワーク関連の開発過程を疑似体験しましたので、次回は開発過程で生じ得る発明の特許化について考えてみたいと思います。
第4回のエントリはこちら
第1回のエントリはこちら
第1回のエントリでは、疑似開発したニューラルネットワークで明細書執筆者を高い精度で推定できたことを示しました。
開発過程では、以下の3パターンの入力データに基づいてニューラルネットワークの学習を行いました。
1.文書表現上の癖
2.論理展開上の癖
3.文書表現上の癖と、論理展開上の癖の双方
以下、それぞれのパターンについて具体的に述べていきます。
●「1.文書表現上の癖」
第1回のエントリで述べたパターンです。このパターンでは、学習前に各明細書について以下の11個の項目を数値化しました。
メインクレーム行数、メインクレーム文字数、サブクレーム平均行数、サブクレーム平均文字数、クレーム1行あたりの「、」の数、クレーム1行あたりの文字数
明細書1段落あたりの「、」の数、明細書1段落あたりの平均文字数、明細書1文あたりの「、」の数、明細書1文あたりの文字数、明細書全文の文字数
学習の詳細は以下の通りです。
・trainingデータ:11個の項目の数値と執筆者を対応づけた300件のデータ
・testデータ:11個の項目の数値と執筆者を対応づけた90件のデータ
・隠れ層:ノード数7の1層
・ミニバッチ:10~50程度
・最適化方法:確率的勾配降下法(stochastic gradient descent)
・イタレーション:50000回
trainingデータで以上の学習を行い、学習後のニューラルネットワークで90件のtestデータの執筆者を推定したところ、正解率は88%でした(図1)。
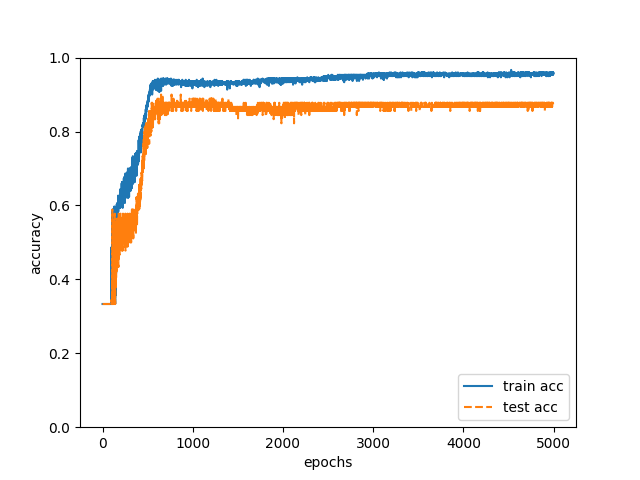
図1
●「2.論理展開上の癖」
このパターンでは、学習前に、各明細書について以下の7個の言葉の数を計測しました。
「しかし」、「なお」、「すなわち」、「また」、「さらに」、「ればよい」、「そして」
私自身は、文書を論理的に展開するために、「主張、解説、論証、例示」という順序で明細書内の文章を書くことが多いです。この順序で文章を書く場合、「解説」の前に「すなわち」が現れます。このような論理展開上の癖は、執筆者毎に異なるため、段落の最初の部分や最後の部分の単語を統計処理すれば執筆者が特定できると考えました。
学習の詳細は「1.文書表現上の癖」と同様です(ただし、隠れ層のノード数は5個)。
trainingデータで以上の学習を行い、学習後のニューラルネットワークで90件のtestデータの執筆者を推定したところ、正解率は79%でした(図2)。
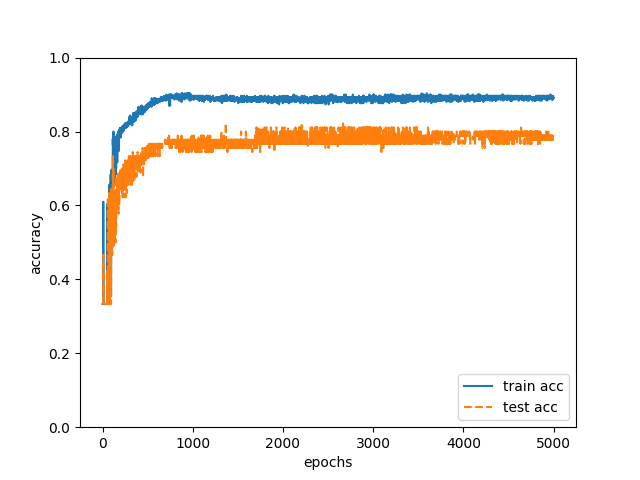
図2
以上のように、「1.文書表現上の癖」を入力データとした場合に88%、「2.論理展開上の癖」を入力データとした場合に79%の正解率が得られました。この結果は私の直感と違いましたので、少し戸惑いました。私自身で執筆者を推定する場合には、句読点の数等よりも執筆者特有の論理展開が現れるか否かに着目するからです。「2.論理展開上の癖」の方が、単に入力データの項目数が少ないために正解率に差が出ているだけかもしれませんが、それでも、執筆者の推定に「1.文書表現上の癖」が有効であることは分かりました。今回の成果に基づいて本気で特許出願をするのであれば「1.文書表現上の癖」を入力データとするという観点で権利化することは外せないでしょう。さらに、比較すると多少正解率が少なくなるものの、「2.論理展開上の癖」であっても79%もの正解率が得られるため、特許出願するならば「2.論理展開上の癖」を入力データとするという観点で出願することにもなるでしょう。
「1.文書表現上の癖」「2.論理展開上の癖」の一方を入力データにした場合に有意な正解率が得られたため、双方を入力データにするとより正確な推定が可能であると考えられます。そこで、
●「3.文書表現上の癖と、論理展開上の癖の双方」
についても学習を行いました。「1.文書表現上の癖」「2.論理展開上の癖」のそれぞれで利用した入力データを結合してtrainingデータとtestデータを作成しました。学習の詳細は「1.文書表現上の癖」と同様です(ただし、隠れ層のノードは11個)。trainingデータで以上の学習を行い、学習後のニューラルネットワークで90件のtestデータの執筆者を推定したところ、正解率は93%でした(図3)。90件のtestデータの中の84件は執筆者を正確に推定できたことになります。
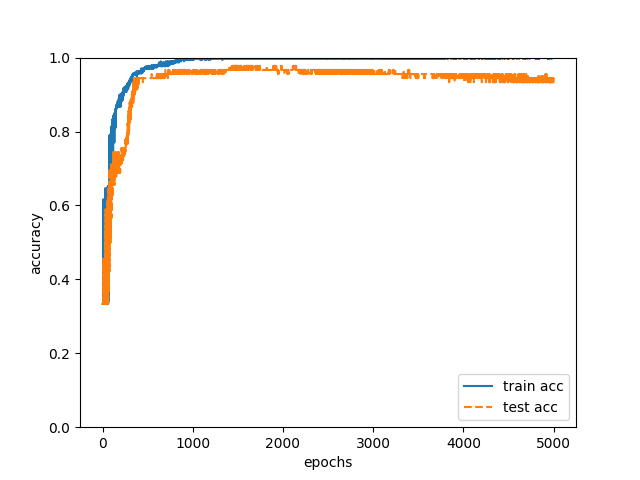
図3
明細書の執筆者を推定するための入力データとして「1.文書表現上の癖」「2.論理展開上の癖」「3.文書表現上の癖と、論理展開上の癖の双方」が有効であることは実証されました。一方、ニューラルネットワークの開発においては、ネットワークの構造を最適化することが必須になると考えられます。次回は、ネットワークの構造を変化させた結果を報告します。
モノ、コトのコストがものすごい速さで低下しているように感じます。私が学生の頃は、学習のためにまず良い本を探すところから始めましたが、良い本に巡り会うまでにやたらと時間コストがかかりました。今では検索すればすぐに良い本を見つけられますし、本を購入しなくてもweb上で良い情報を読むことが可能ですね(google先生ありがとう)。大学レベルの講義も多くのMOOCで無料ですので意欲のある人はいくらでも学習できますね。最近、私は人工知能関連技術の学習に注力していますが、ネットを利用することで極めて低コストで効率的に学習できたように感じます。ネット関連技術に感謝したい。
私は弁理士ですので発明の権利化に興味がありますが、私自身は、一貫して技術を深く理解した後に権利化の戦略を考えるという立場で仕事をしています。そこで、人工知能関連の技術においてもまず技術を深く理解することが自分にとって極めて重要と考えています。深い理解のためには自ら開発するのが一番と考え、特定の目的を達成する技術の開発を疑似体験してみました。開発の疑似体験を通じて、人工知能関連技術の特許化戦略を検討することを目標にしています。まだまだ学習は継続しますが、とりあえず一区切りしましたので、何回かに分けて学習成果を記録しておこうと思います。
開発の概要は以下の通りです。
・目標:特許明細書の特徴から特許明細書の執筆者を特定する人工知能の開発
・利用技術:ニューラルネットワーク
要するに、ニューラルネットワークについて私が学習するために、身近な特許明細書を題材にしたと言うことです。採用したニューラルネットワークは以下の図1の通りです。
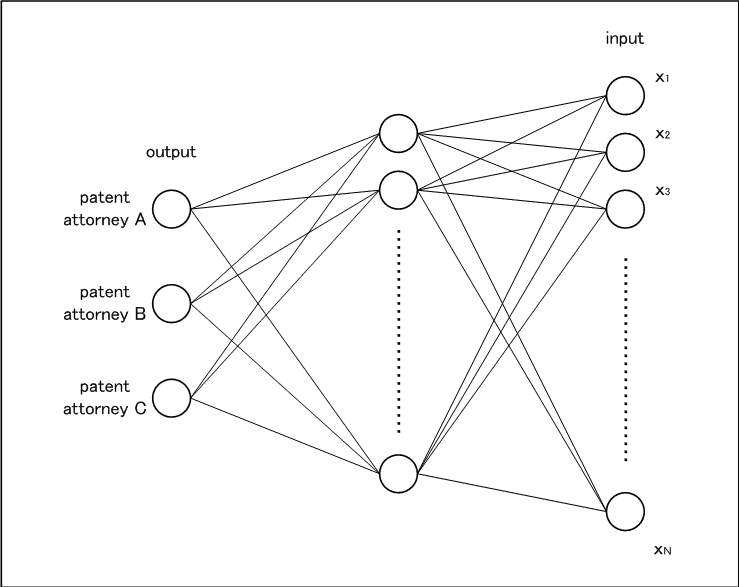
図1
弊所には弁理士が3人おります。各弁理士が執筆した明細書の公開公報を比べると、それぞれの明細書にそれぞれのスタイルがあるように思えます。そこで、各弁理士の明細書の解析結果を入力データとし、弁理士A~Cに対応する3個のノードを出力データとすれば、明細書の特徴を入力し、執筆者を出力するニューラルネットワークを開発できると考えました。
出力ノードは各弁理士に対応させる(ノードの出力の最大値が執筆者の推定結果となる)と決まりました。あとは、1.入力データの決定、2.適切なニューラルネットワークの選定、を行えば、ある程度の出力が得られるニューラルネットワークを開発できそうです。
まずは1.入力データの決定です。とりあえず、ニューラルネットワークは図1に示すように1層の隠れ層を有する構成とし、入力ノードの数と出力ノードの数との中間程度の数で隠れ層のノードを構成しておきます。
さて、入力データは3パターン考えました。
1.文書表現上の癖
2.論理展開上の癖
3.文書表現上の癖と、論理展開上の癖の双方
いずれの特徴も、技術分野に大きく依存せず、全ての明細書に多かれ少なかれ現れるため、これらの特徴を数値化できれば執筆者と1対1に対応する入力データを作成できるのではないかと推定したわけです。
以上のような開発方針が決定したら、次は実践です。
まずは各弁理士の明細書を130件ずつ集めました。これらをテキストデータ化し、テキストデータを複数の観点で統計処理し、得られた複数の値を複数のノードへの入力データとします。このような前処理により、弁理士A~Cのいずれかと複数のノードへの入力データとが対応づけられた教師データを390件生成しました。
今回はこの中の300件をtrainingデータ、90件をtestデータとしました。教師データの中から「1.文書表現上の癖」を表すデータを使って50000回のイタレーションをおこなったところ、以下の図2のようにtrainingデータの正解率(train acc)が96%、testデータの正解率(test acc)が88%になりました。。。。
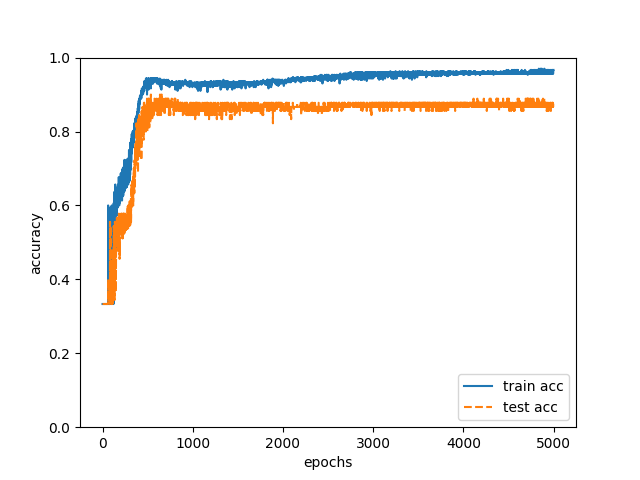
図2
88%。びっくりです。正直うまくいきすぎではないでしょうか。明らかに過学習しているなど、向上の余地はまだまだありますが。普段、各弁理士の執筆原稿を読んでいて、「この明細書は弁理士Aが書いたようだ。」などの推定はできますが、たかが表層的な特徴だけで約90%の確率で執筆者を当てられるなんて。。。意外なことに執筆者の癖は明細書でかなり明らかに現れているのですね。人間にはこの精度で執筆者を推定するなんて到底不可能ですよね。ニューラルネットワークのポテンシャルを実感できました。
さて、長くなってしまいましたので、「1.文書表現上の癖」の具体的な解析、「2.論理展開上の癖」「3.文書表現上の癖と、論理展開上の癖の双方」の具体的な解析については次回に致します。
第2回のエントリはこちら
第3回のエントリはこちら
第4回のエントリはこちら
・参考文献
「ゼロから作るDeepLearning」オライリージャパン 斎藤康毅 著
いくつか読んだ中では解説が大変わかりやすかったです。この本がなければ今回の成果は得られなかったと思います。
「言語研究のためのプログラミング入門」開拓社 淺尾仁彦・李 在鎬 著
明細書のテキストから特徴を抽出するプログラムを作成する際に参考にさせて頂きました。
「Deep Learning」https://www.udacity.com/course/deep-learning–ud730
DeepLearningを自己学習するきっかけを与えてくれた講座です。
ここ数ヶ月、人工知能に関するニュースを聞かない日はありませんね。人工知能の開発あるいは人工知能を利用した製品の開発がここ数年ブームになっているようです。私自身は2年ほど前に「フューチャー・オブ・マインド―心の未来を科学する」(ミチオ・カク著 NHK出版)を読んだことをきっかけに、人間の心や脳を工学的に再現しようとする試みが今までにないステージに到達しつつあることを知りました。この本にはSFと区別できないような研究も多数紹介されており、面白いと感じるもののリアリティのあることだと受け止めることはできませんでした。それでも、かなりの規模の資金が投入され、今までに無いドライビングフォースで研究が進んでいたのだという事実をはじめて知りました。
1年ほど前には毎日のように人工知能に関するニュースが報じられていたように思います。シンギュラリティなんかも頻繁に論じられていました。
技術に関するニュースには過度に期待を抱かせるものが多いため、普段であればほとんどのニュースを読み流します。しかし、連日のように報道され、中には驚くような成果も多かったため、「これはもしかしたら本物かもしれない。」このように感じるようになりました。この頃私自身はニュースで人工知能を知っている程度であり、人工知能とは何を指すのか?なぜ突然ブームになったのか?など、詳しい知識はありませんでした。そこで、人工知能に関する種々の本を読みはじめ、人工知能のプログラミングについても勉強しはじめました。
当時読んだ本の中では、ベストセラーになっていた「人工知能は人間を超えるか」(松尾 豊著 角川EPUB選書)が印象深かったです。今までに3回ほど読んだでしょうか。
この本では、「いまの人工知能は、実力より期待感の方がはるかに大きくなっている。」と冷静に分析されています。それでも、「現在の人工知能は「大きな飛躍の可能性」に賭けてもいいような段階だ。」と指摘されています。過度にセンセーショナルに書かない姿勢が信頼感を醸成しているように思えました。
この本によると、現在のブームにつながるブレークスルーは確かにあったようで、
「1層ずつ階層毎に学習していく」ことと
「自己符号化器を使う」こと
でブレークスルーを果たしたようです。
これらの要素技術を使うことで「特徴表現をコンピュータが自らつくり出す」ことが可能になった。これが大発明であるということでした。これは、例えば、コンピュータが画像認識をする際に画像のどの特徴に着目するのかを、コンピュータ自ら決定できるようになったということのようです。今までは、人間がどの特徴に着目するのか教えていたため、認識率が向上しなかったと。
一方、「深層学習 Deep Learning (監修:人工知能学会)」では、「今回のブレークスルーを生んだとされている「層毎の貪欲学習」も、実問題でうまくゆくことが経験的に知られてはいるが、(中略)、内部表現が局所収束を避けた最適なものになっているという保証はない」と述べられています。うまくいく事例はたくさんあるが、「「ブレークスルー」の原因はこれ。」というように明確に言い切ることは難しいのかなという印象を持ちました。
確定的なことは言えないと学者さんに言われるといまいちすっきりしないのですが、どうやらキモは自己符号化器を利用して層をディープにできたことにあるようです(このように私は解釈しました)。
いずれにしても、いくつかの要素技術の改善によっていくつかの分野で劇的な結果が得られたことによって今日のブームに至ったらしい。このあたりの事情を知ったのが1年ほど前でした。シンギュラリティや人工知能によって失われる職業などについても盛んに報道されていましたが、少し調べてみると「一般人も興味を持つような目に見える進歩がいくつかのブレークスルーによって達成された。」といった程度のことであり、人工知能が人間の知能を超えると思わせるような具体例は、私の知る限り、提示されていなかったと記憶しています。
従って、私は当時、「いくらなんでも近い将来に人間の能力を超える人工知能が誕生するシンギュラリティなんてあり得ないのでは?ターミネーターじゃあるまいし。」などと考えていました。「自己符号化器による層毎の学習で内部表現を学習できたと言っても、そのことと、人間を凌駕する人工知能との間には、相当な開きがあるよね?」と。「人工知能は人間を超えるか」の著者である松尾先生も「人工知能が人間を征服する心配をする必要はない。」と述べられており、「人間の能力を超える人工知能」の出現という意味でのシンギュラリティについて、多くの研究者は否定的だったのではないでしょうか。
ところが、、、最近は、有名な学者さんが「シンギュラリティが来ることにリアリティを感じない方が主流でしたが、だんだん、だんだん、本当だと思う人が増えてきてて。」などと発言されていらっしゃる(「よくわかる人工知能 最先端の人だけが知っているディープラーニングのひみつ」(清水亮 著:KADOKAWA))。多くの人が予想していた速度を超えてすさまじい速度で技術が進歩しているということらしい。。。。
まじっすか?
これって、「シンギュラリティは近い―人類が生命を超越するとき」(レイ・カーツワイル著 NHK出版)で述べられている指数関数的な成長が真実だということなのでしょうか。
私自身はシンギュラリティについてはやっぱり懐疑的(というか想像力が追いつかない)ですが、それでも「近い将来の変革に備えねばなるまい。」最近はこのように考えるようになりました。
まず特許実務家として、あらゆる産業で人工知能の利用価値が高まることに備えようと思います。ここ一年ぐらい続けている要素技術に関する知識の学習は今後も続けようと思います。また、人工知能に関する技術を権利化する際の特許戦略を常日頃から考えています。進歩性の訴求ポイント、明細書への書き込み、技術進歩の速さに対する配慮など、種々の点で従来の実務と異なる視点が必要のように感じます。
さらに、本当にシンギュラリティに達するか否かはともかく、人工知能が人間の能力を徐々に獲得していく世界に生きる一人の人間として自己の存在意義を問い続けようと考えています。人工知能にできない能力を備えた人間とはどういう存在なのかと。そして、人工知能が切り開く新しい世界が多くの人類にとって明るい世界であることを期待したいと思います。
※上述の書籍に関する解釈はこのブログの執筆者個人の解釈であり、分析は執筆者にあります。
少人数で活発に議論するスタイルにしたいと思いますので、参加者は多くても10名程度にしたいと考えています。
参加者の経験値に差がありすぎると議論が一方的になりやすいため、実務経験5年以上の弁理士または年間10件以上の特許出願を扱う特許部所属の方を募集しようと思います。技術分野はソフトウェア、制御、電気、機械に限定します。私自身、化学、バイオ等の明細書執筆経験が無く、メンバーにとって関心のある技術分野が揃っていないと勉強会の効果が薄くなるように思えますので。
どのようなスタイルでもよいのですが、特許明細書の品質にダイレクトに効くような勉強会にしたいです。
今考えているのは、
・当番が公開公報を選択し、実施形態部分をメンバーに事前配布
・メンバーは実施形態部分を読み、勉強会の日までに各自クレームを作成
・当日は各メンバーのクレームをみんなで分析し、意見交換
こんなスタイルです。むろん、勉強会開始前にはメンバーで勉強会のスタイルや場所、時間、頻度等を相談し、多くの方が賛同できるスタイルにフィックスします。実務書(Landis等)の輪読でもよいかと思います。
業界は繁忙期に入っていますので、繁忙期中はメンバー募集と勉強会スタイルの相談期間とし、4月頃に勉強会を開始したいと思います。
興味のある方はふるってご参加ください。参加を決めていないが問い合わせしたいという方も歓迎です。コンタクトページからメールを送っていただくか、ウェブサイト下部の電話番号にお電話をいただく(担当:岩上)ことで参加を受け付けます。